
Homework Answers
(X, Y) is an instance labelled set. If (x,y) is linearly separable then it means we can have a line which will separate this set into two groups having different properties. No element of one group will be on another side of the line.
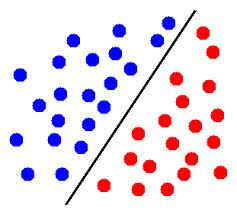
So we can have a logistic regression model Hsig which will produce zero loss, loss being error calculated if one element is on another side of the line. So any set X_train from the full set will also follow the same property and it will also not have any loss.
b)
If the logistic regression model produces zero loss on the training set, we cannot say anything about the set being linearly separable or not, because we are not guaranteed that the test set will also produce zero loss.
Similarly, even if the loss is zero on X_train and we have linearly separable set we are not sure that the regression line is the same line which divides the set. It can produce some loss while testing and we can eliminate this loss by taking more iterations of the training.
Add Answer to:
Machine Learning
4·Let (X.J) be a instance-label set with χ e Rn and let χ1ram be...
a Suppose {יוע ע "ע 3is a linearly dependent set in R. Let T : Rn...
 a Suppose {יוע ע "ע 3is a linearly dependent set in R. Let T : Rn Rm be a linear transformation. Explain why { T(L| ), Tjas), Γ(L3 ) must be linearly dependent in Rin. b Suppose (x, t.,) is a linearly independent set in R". Let Tbe a linear transformation. Do T(Li ) , T(L, ), T(ש ) and explain why not. have to be linearly independent in R ? Explain why, or give a counterexample
a Suppose {יוע ע "ע 3is a linearly dependent set in R. Let T : Rn Rm be a linear transformation. Explain why { T(L| ), Tjas), Γ(L3 ) must be linearly dependent in Rin. b Suppose (x, t.,) is a linearly independent set in R". Let Tbe a linear transformation. Do T(Li ) , T(L, ), T(ש ) and explain why not. have to be linearly independent in R ? Explain why, or give a counterexample
Question 8 (Chapters 6-7) 12+2+2+3+2+4+4-19 marks] Let 0メS C Rn and fix E S. For a E R consider the following optimization problem: (Pa) min a r, and define the set K(S,x*) := {a E Rn : x. is a...
 Question 8 (Chapters 6-7) 12+2+2+3+2+4+4-19 marks] Let 0メS C Rn and fix E S. For a E R consider the following optimization problem: (Pa) min a r, and define the set K(S,x*) := {a E Rn : x. is a solution of (PJ) (a) Prove that K(S,'). Hint: Check 0 (b) Prove that K(S, r*) is a cone. (c) Prove that K(S,) is convex d) Let S C S2 and fix eS. Prove that K(S2, ) cK(S, (e) Ifx. E...
Question 8 (Chapters 6-7) 12+2+2+3+2+4+4-19 marks] Let 0メS C Rn and fix E S. For a E R consider the following optimization problem: (Pa) min a r, and define the set K(S,x*) := {a E Rn : x. is a solution of (PJ) (a) Prove that K(S,'). Hint: Check 0 (b) Prove that K(S, r*) is a cone. (c) Prove that K(S,) is convex d) Let S C S2 and fix eS. Prove that K(S2, ) cK(S, (e) Ifx. E...
Let A be an m × n matrix The image of A is the set of vectors m(A) = {y : y = Ax for some x E Rn)...
 Let A be an m × n matrix The image of A is the set of vectors m(A) = {y : y = Ax for some x E Rn). which is a vector space The dimension of im(A) is called the rank of A, denoted by rank(A) (a) Find the rank of the matrix -62 1110 142 441 100-234 -1786478 46 -115 -46 -46 69 -122 85 150 174 -685 and enter in the box below rank(A) in应答 评分: 01...
Let A be an m × n matrix The image of A is the set of vectors m(A) = {y : y = Ax for some x E Rn). which is a vector space The dimension of im(A) is called the rank of A, denoted by rank(A) (a) Find the rank of the matrix -62 1110 142 441 100-234 -1786478 46 -115 -46 -46 69 -122 85 150 174 -685 and enter in the box below rank(A) in应答 评分: 01...
Question 7 (Chapters 6-7) 2+2+2+3+2+4+4-19 mark Let 0メs c Rn and fix r' E S. For a R" consider the followi...
 Question 7 (Chapters 6-7) 2+2+2+3+2+4+4-19 mark Let 0メs c Rn and fix r' E S. For a R" consider the following optimization problem: (Pa) min ar res and define the set K(S,) (aER z" is a solution of (Pa)) (e) If z' e int(S), prove that K(S, (0) (1) If possible, find a set S CR" and s* E S such that K(S,) (g) Let SB, 0.1] (rR l2l3 1) (the closed (, unit ball) and consider (1,0)7. Prove that...
Question 7 (Chapters 6-7) 2+2+2+3+2+4+4-19 mark Let 0メs c Rn and fix r' E S. For a R" consider the following optimization problem: (Pa) min ar res and define the set K(S,) (aER z" is a solution of (Pa)) (e) If z' e int(S), prove that K(S, (0) (1) If possible, find a set S CR" and s* E S such that K(S,) (g) Let SB, 0.1] (rR l2l3 1) (the closed (, unit ball) and consider (1,0)7. Prove that...
Question 1 [22 marks] (Chapt ers 2, 3, 4, 5, and 6) Let A e Rn...
 Question 1 [22 marks] (Chapt ers 2, 3, 4, 5, and 6) Let A e Rn be an (n x n) matrix and be R. Consider the problem 1 (P2) min2+ s.t. xe R" 1Ax-bil2 1 where & > O is fixed and Il IIl denot es the 2-norm. Call g.(x)=l|2 the objective function of problem (P2) 1Ax-bl2 i) [3 marks] Compute the gradient of g, and use it to show that the solution xi of this problem verifies (I+EATA)(x)...
Question 1 [22 marks] (Chapt ers 2, 3, 4, 5, and 6) Let A e Rn be an (n x n) matrix and be R. Consider the problem 1 (P2) min2+ s.t. xe R" 1Ax-bil2 1 where & > O is fixed and Il IIl denot es the 2-norm. Call g.(x)=l|2 the objective function of problem (P2) 1Ax-bl2 i) [3 marks] Compute the gradient of g, and use it to show that the solution xi of this problem verifies (I+EATA)(x)...
Need help with stats true or false questions Decide (with short explanations) whether the following statements are true or false a) We consider the model y-Ao +A(z) +E. Let (-0.01, 1.5) be a 95% con...
 Need help with stats true or false questions
Decide (with short explanations) whether the following statements are true or false a) We consider the model y-Ao +A(z) +E. Let (-0.01, 1.5) be a 95% confidence interval for A In this case, a t-test with significance level 1% rejects the null hypothesis Ho : A-0 against a two sided alternative. b) Complicated models with a lot of parameters are better for prediction then simple models with just a few parameters c)...
Need help with stats true or false questions
Decide (with short explanations) whether the following statements are true or false a) We consider the model y-Ao +A(z) +E. Let (-0.01, 1.5) be a 95% confidence interval for A In this case, a t-test with significance level 1% rejects the null hypothesis Ho : A-0 against a two sided alternative. b) Complicated models with a lot of parameters are better for prediction then simple models with just a few parameters c)...
Could you please answer the question Q1 to Q3. Write the answer clearly and step by step. 1 Let U = {1, 2, 3, 4, 5, 6, 7} be the universe. Form the set A as follows: Read off your seven digit student...
 Could you please answer the question Q1 to Q3. Write the answer
clearly and step by step.
1 Let U = {1, 2, 3, 4, 5, 6, 7} be the universe. Form the set A as follows: Read off your seven digit student number from left to right. For the first digit ni include the number 1 in A if ni is even otherwise omit 1 from A. Now take the second digit n2 and include the number 2 in...
Could you please answer the question Q1 to Q3. Write the answer
clearly and step by step.
1 Let U = {1, 2, 3, 4, 5, 6, 7} be the universe. Form the set A as follows: Read off your seven digit student number from left to right. For the first digit ni include the number 1 in A if ni is even otherwise omit 1 from A. Now take the second digit n2 and include the number 2 in...
Implicit Function Theorem in Two Variables: Let g: R2 → R be a smooth function. Set {(z, y) E R2 ...
 Implicit Function Theorem in Two Variables: Let g: R2 → R be a smooth function. Set {(z, y) E R2 | g(z, y) = 0} S Suppose g(a, b)-0 so that (a, b) E S and dg(a, b)メO. Then there exists an open neighborhood of (a, b) say V such that SnV is the image of a smooth parameterized curve. (1) Verify the implicit function theorem using the two examples above. 2) Since dg(a,b) 0, argue that it suffices to...
Implicit Function Theorem in Two Variables: Let g: R2 → R be a smooth function. Set {(z, y) E R2 | g(z, y) = 0} S Suppose g(a, b)-0 so that (a, b) E S and dg(a, b)メO. Then there exists an open neighborhood of (a, b) say V such that SnV is the image of a smooth parameterized curve. (1) Verify the implicit function theorem using the two examples above. 2) Since dg(a,b) 0, argue that it suffices to...
1. In the simple regression model y = + β1x + u, suppose that E (u)...
 1. In the simple regression model y = + β1x + u, suppose that E (u) 0. Letting oo-E(u), show that the model can always be rewrit ten with the same slope, but a new intercept and error, where the new error has a zero expected value 2. The data set BWGHT contains data on births to women in the United States. Two variables of interest are the dependent variable, nfan birth weight in ounces (bught), and an explanatory variable,...
1. In the simple regression model y = + β1x + u, suppose that E (u) 0. Letting oo-E(u), show that the model can always be rewrit ten with the same slope, but a new intercept and error, where the new error has a zero expected value 2. The data set BWGHT contains data on births to women in the United States. Two variables of interest are the dependent variable, nfan birth weight in ounces (bught), and an explanatory variable,...
The Quantitative Environmental Learning Project reported widths and lengths (in centimeters) of a sample of 88...
The Quantitative Environmental Learning Project reported widths and lengths (in centimeters) of a sample of 88 Puget Sound butter clams. Output is shown for the regression of length on width. Pearson correlation of Width and Length = 0.989 The regression equation is Length = 0.257 + 1.22 Width Predictor Coef SE Coef T P Constant 0.25689 0.09293 2.76 0.007 Width 1.22013 0.01940 62.89 XXXXX S = 0.3253 R-Sq = 97.9% R-Sq(adj) = 97.8% (a) Why would it be natural for the relationship...
 a Suppose {יוע ע "ע 3is a linearly dependent set in R. Let T : Rn Rm be a linear transformation. Explain why { T(L| ), Tjas), Γ(L3 ) must be linearly dependent in Rin. b Suppose (x, t.,) is a linearly independent set in R". Let Tbe a linear transformation. Do T(Li ) , T(L, ), T(ש ) and explain why not. have to be linearly independent in R ? Explain why, or give a counterexample
a Suppose {יוע ע "ע 3is a linearly dependent set in R. Let T : Rn Rm be a linear transformation. Explain why { T(L| ), Tjas), Γ(L3 ) must be linearly dependent in Rin. b Suppose (x, t.,) is a linearly independent set in R". Let Tbe a linear transformation. Do T(Li ) , T(L, ), T(ש ) and explain why not. have to be linearly independent in R ? Explain why, or give a counterexample
 Question 8 (Chapters 6-7) 12+2+2+3+2+4+4-19 marks] Let 0メS C Rn and fix E S. For a E R consider the following optimization problem: (Pa) min a r, and define the set K(S,x*) := {a E Rn : x. is a solution of (PJ) (a) Prove that K(S,'). Hint: Check 0 (b) Prove that K(S, r*) is a cone. (c) Prove that K(S,) is convex d) Let S C S2 and fix eS. Prove that K(S2, ) cK(S, (e) Ifx. E...
Question 8 (Chapters 6-7) 12+2+2+3+2+4+4-19 marks] Let 0メS C Rn and fix E S. For a E R consider the following optimization problem: (Pa) min a r, and define the set K(S,x*) := {a E Rn : x. is a solution of (PJ) (a) Prove that K(S,'). Hint: Check 0 (b) Prove that K(S, r*) is a cone. (c) Prove that K(S,) is convex d) Let S C S2 and fix eS. Prove that K(S2, ) cK(S, (e) Ifx. E...
 Let A be an m × n matrix The image of A is the set of vectors m(A) = {y : y = Ax for some x E Rn). which is a vector space The dimension of im(A) is called the rank of A, denoted by rank(A) (a) Find the rank of the matrix -62 1110 142 441 100-234 -1786478 46 -115 -46 -46 69 -122 85 150 174 -685 and enter in the box below rank(A) in应答 评分: 01...
Let A be an m × n matrix The image of A is the set of vectors m(A) = {y : y = Ax for some x E Rn). which is a vector space The dimension of im(A) is called the rank of A, denoted by rank(A) (a) Find the rank of the matrix -62 1110 142 441 100-234 -1786478 46 -115 -46 -46 69 -122 85 150 174 -685 and enter in the box below rank(A) in应答 评分: 01...
 Question 7 (Chapters 6-7) 2+2+2+3+2+4+4-19 mark Let 0メs c Rn and fix r' E S. For a R" consider the following optimization problem: (Pa) min ar res and define the set K(S,) (aER z" is a solution of (Pa)) (e) If z' e int(S), prove that K(S, (0) (1) If possible, find a set S CR" and s* E S such that K(S,) (g) Let SB, 0.1] (rR l2l3 1) (the closed (, unit ball) and consider (1,0)7. Prove that...
Question 7 (Chapters 6-7) 2+2+2+3+2+4+4-19 mark Let 0メs c Rn and fix r' E S. For a R" consider the following optimization problem: (Pa) min ar res and define the set K(S,) (aER z" is a solution of (Pa)) (e) If z' e int(S), prove that K(S, (0) (1) If possible, find a set S CR" and s* E S such that K(S,) (g) Let SB, 0.1] (rR l2l3 1) (the closed (, unit ball) and consider (1,0)7. Prove that...
 Question 1 [22 marks] (Chapt ers 2, 3, 4, 5, and 6) Let A e Rn be an (n x n) matrix and be R. Consider the problem 1 (P2) min2+ s.t. xe R" 1Ax-bil2 1 where & > O is fixed and Il IIl denot es the 2-norm. Call g.(x)=l|2 the objective function of problem (P2) 1Ax-bl2 i) [3 marks] Compute the gradient of g, and use it to show that the solution xi of this problem verifies (I+EATA)(x)...
Question 1 [22 marks] (Chapt ers 2, 3, 4, 5, and 6) Let A e Rn be an (n x n) matrix and be R. Consider the problem 1 (P2) min2+ s.t. xe R" 1Ax-bil2 1 where & > O is fixed and Il IIl denot es the 2-norm. Call g.(x)=l|2 the objective function of problem (P2) 1Ax-bl2 i) [3 marks] Compute the gradient of g, and use it to show that the solution xi of this problem verifies (I+EATA)(x)...
 Need help with stats true or false questions
Decide (with short explanations) whether the following statements are true or false a) We consider the model y-Ao +A(z) +E. Let (-0.01, 1.5) be a 95% confidence interval for A In this case, a t-test with significance level 1% rejects the null hypothesis Ho : A-0 against a two sided alternative. b) Complicated models with a lot of parameters are better for prediction then simple models with just a few parameters c)...
Need help with stats true or false questions
Decide (with short explanations) whether the following statements are true or false a) We consider the model y-Ao +A(z) +E. Let (-0.01, 1.5) be a 95% confidence interval for A In this case, a t-test with significance level 1% rejects the null hypothesis Ho : A-0 against a two sided alternative. b) Complicated models with a lot of parameters are better for prediction then simple models with just a few parameters c)...
 Could you please answer the question Q1 to Q3. Write the answer
clearly and step by step.
1 Let U = {1, 2, 3, 4, 5, 6, 7} be the universe. Form the set A as follows: Read off your seven digit student number from left to right. For the first digit ni include the number 1 in A if ni is even otherwise omit 1 from A. Now take the second digit n2 and include the number 2 in...
Could you please answer the question Q1 to Q3. Write the answer
clearly and step by step.
1 Let U = {1, 2, 3, 4, 5, 6, 7} be the universe. Form the set A as follows: Read off your seven digit student number from left to right. For the first digit ni include the number 1 in A if ni is even otherwise omit 1 from A. Now take the second digit n2 and include the number 2 in...
 Implicit Function Theorem in Two Variables: Let g: R2 → R be a smooth function. Set {(z, y) E R2 | g(z, y) = 0} S Suppose g(a, b)-0 so that (a, b) E S and dg(a, b)メO. Then there exists an open neighborhood of (a, b) say V such that SnV is the image of a smooth parameterized curve. (1) Verify the implicit function theorem using the two examples above. 2) Since dg(a,b) 0, argue that it suffices to...
Implicit Function Theorem in Two Variables: Let g: R2 → R be a smooth function. Set {(z, y) E R2 | g(z, y) = 0} S Suppose g(a, b)-0 so that (a, b) E S and dg(a, b)メO. Then there exists an open neighborhood of (a, b) say V such that SnV is the image of a smooth parameterized curve. (1) Verify the implicit function theorem using the two examples above. 2) Since dg(a,b) 0, argue that it suffices to...
 1. In the simple regression model y = + β1x + u, suppose that E (u) 0. Letting oo-E(u), show that the model can always be rewrit ten with the same slope, but a new intercept and error, where the new error has a zero expected value 2. The data set BWGHT contains data on births to women in the United States. Two variables of interest are the dependent variable, nfan birth weight in ounces (bught), and an explanatory variable,...
1. In the simple regression model y = + β1x + u, suppose that E (u) 0. Letting oo-E(u), show that the model can always be rewrit ten with the same slope, but a new intercept and error, where the new error has a zero expected value 2. The data set BWGHT contains data on births to women in the United States. Two variables of interest are the dependent variable, nfan birth weight in ounces (bught), and an explanatory variable,...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago