Problem 2. Figure 1 shows medical records from a fictitious hospital. ID QI SV Zip Code...
Problem 2.
Figure 1 shows medical records from a fictitious hospital.
|
ID |
QI |
SV |
||
|
Zip Code |
Age |
Nationality |
Condition |
|
|
1 |
13053 |
28 |
Russian |
Heart Disease |
|
2 |
13053 |
36 |
Japanese |
Flu |
|
3 |
13068 |
35 |
American |
Cancer |
|
4 |
13068 |
29 |
American |
Heart Disease |
|
5 |
13068 |
21 |
Japanese |
Viral Infection |
|
6 |
14850 |
46 |
Indian |
Flu |
|
7 |
13053 |
31 |
American |
Cancer |
|
8 |
13053 |
23 |
American |
Viral Infection |
|
9 |
14853 |
50 |
Indian |
Cancer |
|
10 |
14853 |
55 |
Russian |
Heart Disease |
|
11 |
14850 |
47 |
American |
Viral Infection |
|
12 |
14850 |
49 |
American |
Viral Infection |
|
13 |
13053 |
37 |
Indian |
Cancer |
|
14 |
13068 |
36 |
Japanese |
Cancer |
|
15 |
13068 |
38 |
Russian |
Flu |
Figure 1: Inpatient microdata
Now you are asked to anonymize the above table according to the following requirements. Note that when you do the anonymization, you should try to generalize the QI with minimum changes (i.e., the changed values should be as accurate as possible).
- GeneralizetheQIvaluesofthetablefor2-anonymity.
- GeneralizetheQIvaluesofthetablefor4-anonymity.
- Generalize the QI values of the table for3-diversity.
- Instead of generalize QI values, now you are asked to use the anatomy method to develop the 3-diversity.
Homework Answers
 Explanation:-Figure 2 shows a
4-anonymous table derived from the table in Figure 1 (here “*”
denotes a suppressed value so, for example, “zip code = 1485*”
means that the zip code is in the range [14850−14859] and “age=3*”
means the age is in the range [30 − 39]). Note that in the
4-anonymous table, each tuple has the same values for the
quasi-identifier as at least three other tuples in the table.
Because of its conceptual simplicity, k-anonymity has been widely
discussed as a viable definition of privacy in data publishing, and
due to algorithmic advances in creating k-anonymous versions of a
data set [3, 6, 16, 18, 21, 24, 25], k-anonymity has grown in
popularity. However, does k-anonymity really guarantee privacy? In
the next section, we will show that the answer to this question is
interestingly no.
Explanation:-Figure 2 shows a
4-anonymous table derived from the table in Figure 1 (here “*”
denotes a suppressed value so, for example, “zip code = 1485*”
means that the zip code is in the range [14850−14859] and “age=3*”
means the age is in the range [30 − 39]). Note that in the
4-anonymous table, each tuple has the same values for the
quasi-identifier as at least three other tuples in the table.
Because of its conceptual simplicity, k-anonymity has been widely
discussed as a viable definition of privacy in data publishing, and
due to algorithmic advances in creating k-anonymous versions of a
data set [3, 6, 16, 18, 21, 24, 25], k-anonymity has grown in
popularity. However, does k-anonymity really guarantee privacy? In
the next section, we will show that the answer to this question is
interestingly no.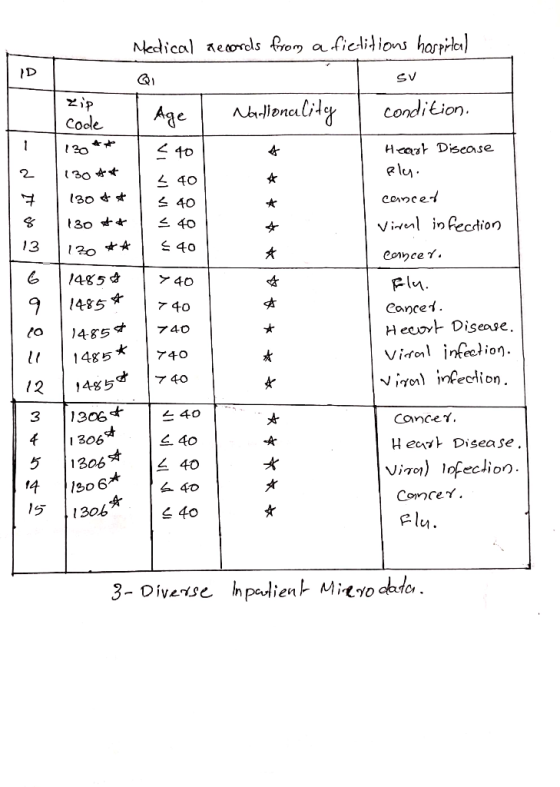
consider the inpatient records shown in Figure 1. We present a 3-diverse version of the table in Figure 3. Comparing it with the 4-anonymous table in Figure 2 we see that the attacks against the 4-anonymous table are prevented by the 3-diverse table. For example, Alice cannot infer from the 3-diverse table that Bob (a 31 year old American from zip code 13053) has cancer. Even though Umeko (a 21 year old Japanese from zip code 13068) is extremely unlikely to have heart disease, Alice is still unsure whether Umeko has a viral infection or cancer. The ℓ-diversity principle advocates ensuring ℓ “well represented” values for the sensitive attribute in every q ⋆ -block, but does not clearly state what “well represented” means. Note that we called it a “principle” instead of a theorem — we will use it to give two concrete instantiations of the ℓ-diversity principle and discuss their relative trade-offs
Add Answer to:
Problem 2.
Figure 1 shows medical records from a
fictitious hospital.
ID
QI
SV
Zip Code...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago