1. The variance in a production process is an important measure of the quality of the...
1. The variance in a production process is an
important measure of the quality of the process. A large variance
often signals an opportunity for improvement in the process by
finding ways to reduce the process variance. The following sample
data show the weight of bags (in pounds) produced on two machines:
machine 1 and 2.
m1 = (2.95, 3.45, 3.50, 3.75, 3.48, 3.26, 3.33, 3.20, 3.16, 3.20,
3.22, 3.38, 3.90, 3.36, 3.25, 3.28, 3.20, 3.22, 2.98, 3.45, 3.70,
3.34, 3.18, 3.35, 3.12)
m2 = (3.22, 3.30, 3.34, 3.28, 3.29, 3.25, 3.30, 3.27, 3.38, 3.34,
3.35, 3.19, 3.35, 3.05, 3.36, 3.28, 3.30, 3.28, 3.30, 3.20, 3.16,
3.33)
a) Provide descriptive statistical summaries of the
data for each model; in particular, the sample variance and the
sample size for each machine.
Please copy your R code and the result and paste
them here.
b) Conduct a statistical test to determine whether there is a significant difference between the variances in the bag weights for two machines. First, clearly formulating your hypotheses below.
c) Compute the test statistic.
Please copy your R code and the result and paste
them here.
d) Compute the p value.
Please copy your R code and the result and paste
them here.
e) Use a .05 level of significance to compute both
critical values for your test statistic.
Please copy your R code and the result and paste
them here.
f) Use a .05 level of significance. What is your conclusion?
g) Use the function var.test() in R to run the test
directly to confirm your results above are correct.
Please copy your R code and the result and paste
them here.
h) Construct a 95% confidence interval for the
variance of the weight of bags produced on machine 1.
Please copy your R code and the result and paste
them here.
i) Construct a 95% confidence interval for the standard
deviation of the weight of bags produced on machine 2.
Please copy your R code and the result and paste
them here.
j) Which machine, if either, provides the greater
opportunity for quality improvements?
Homework Answers
A) R code to print descriptive summaries
#create the sample data
m1<-c(2.95,3.45,3.50,3.75,3.48,3.26,3.33,3.20,3.16,3.20,3.22,3.38,3.90,3.36,3.25,3.28,3.20,3.22,2.98,3.45,3.70,3.34,3.18,3.35,3.12)
m2<-c(3.22,3.30,3.34,3.28,3.29,3.25,3.30,3.27,3.38,3.34,3.35,3.19,3.35,3.05,3.36,3.28,3.30,3.28,3.30,3.20,3.16,3.33)
#a) descriptive summaries
summary(m1)
summary(m2)
#get the sample sizes
n1<-length(m1)
n2<-length(m2)
#get the sample variances
v1<-var(m1)
v2<-var(m2)
print(paste("The sample size of m1 is",n1,"and the sample variance
is",round(v1,4)))
print(paste("The sample size of m2 is",n2,"and the sample variance
is",round(v2,4)))
#--get the following output
![> #create the sample data > mi<-c (2.95,3.45,3.50,3.75,3.48,3.26, 3.33,3.20,3.16,3.20,3.22,3.38,3.90,3.36,3.25,3.28,3.20,3. > m2<-c (3.22,3.30,3.34,3.28,3.2,3.25,3 ·30,3.27,3.38,3.34,3.3,3.1 , 3 . 35 , 3.0 , 3.36, 3. 28,3.30,3. > fa) descriptive summaries > summary (m1) 5 9 5 5 5 2 5 5 5 9 5 9 8 5 5 5 5 5 Min. 1st u Median 3rd Qu. Max. 2.950 3.200 3.280 3.328 3.450 3.900 > summary (m2) Min. 1st Qu. Median 3rd Qu. Max. 3.050 3.255 3.295 3.278 3.337 3.380 > #get the sample sizes > ni<-length (m1) > n2<-length (m2) > #get the sample variances > v1<-var (ml) > v2<-var (m2) > print (paste (The sample size of ml is,n1, and the sample variance is, round (vi, 4))) [1] The sample size of ml is 25 and the sample variance is 0.0489 > print (paste(The sample size of m2 is, n2, and the sample variance is, zound (v2,))) [1] The sample size of m2 is 22 and the sample variance is 0.0059](http://img.homeworklib.com/questions/e25163e0-3c43-11eb-8d9b-e1c3655dedbd.png?x-oss-process=image/resize,w_560)
b) Let  be the true variance in bag weights for
machine 1 and
be the true variance in bag weights for
machine 1 and  be the true variance in bag weights for
machine 2.
be the true variance in bag weights for
machine 2.
we want to conduct a statistical test to determine whether there
is a significant difference between the variances
in the bag weights for two machines. this means we want to test if

the following are the hypotheses that we want to test

C) the test statistic is

R-code
#c) test statistics
f<-v1/v2
print(paste("The test statistics is F=",round(f,4),sep=""))
## get the following output

D) This is a 2 tailed test. P-value is the sum of area under the 2 tails, that is P(F<1/8.2844) +P(F>8.2844). Since the areas are the same,
the p-value is 2*P(F>8.2844). The numerator df is n1-1 = 25-1=24
and the denominator df is n2-1=22-1=21
Rcode is
#d) p-value
pvalue<-2*pf(f,df1=n1-1,df2=n2-1,lower.tail=FALSE)
print(paste("The p-value is ",round(pvalue,9),sep=""))
#get the following

E) this is a 2 tailed test. Hence
the upper tail value of critical value of F is
 with degrees of freedom n1-1=24 and
n2-1=21
with degrees of freedom n1-1=24 and
n2-1=21
In terms of the left tail this can be experessed as
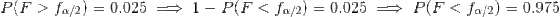
the lower tail value of critical value of F is
 with degrees of freedom n1-1=24 and
n2-1=21
with degrees of freedom n1-1=24 and
n2-1=21
R-code to get the values
#E)Critical values
alpha<-0.05
#get the lower tail critical value
lcf<-qf(alpha/2,df=n1-1,df2=n2-1)
#get the upper tail critical value
ucf<-qf(1-alpha/2,df=n1-1,df2=n2-1)
print(paste("The lower critical value is",round(lcf,4),",the upper
critical value is",round(ucf,4)))
#get the following

F) We can see the p-value is less than alpha = 0.05. We can also see that the the tets statistics of 8.2844 is greater than the upper critical value of 2.3675.
We reject the null hypothesis
We conclude that there is sufficient evidence to support the claim that there is a significant difference between the variances in the bag weights for two machines.
G) R code
#g use var.test
var.test(m1,m2,ratio = 1,alternative = c("two.sided"),conf.level =
0.95)
# get the following

the results match that of earlier
H) 95% confidence interval indicates that the total area under 2
tails is  or the area under each tail is 0.025. The
critical value for the upper tail is
or the area under each tail is 0.025. The
critical value for the upper tail is 
the lower tail critical value is

confidence interval for variance is
![\left[ \frac{(n-1)s^2}{\chi^2_U}, \frac{(n-1)s^2}{\chi^2_L} \right]](http://img.homeworklib.com/questions/e8842bb0-3c43-11eb-9ffa-21a1e187abb6.gif?x-oss-process=image/resize,w_560)
R code for machine 1
#h) 95% confidence interval for machine 1
alpha<-0.05
#get the lower tail critical value
chil<-qchisq(alpha/2,df=n1-1)
#get the upper tail critical value
chiu<-qchisq(1-alpha/2,df=n1-1)
#get the lower value of CI
lci1<-(n1-1)*v1/chiu
#get the upper value of CI
uci1<-(n1-1)*v1/chil
print(paste("The 95% confidence interval for the variance of the
weight of bags produced on machine 1 is
[",round(lci1,4),",",round(uci1,4),"]",sep=""))
# get the output

I) 95% confidence interval for standard deviation is
![\left[ \sqrt\frac{(n-1)s^2}{\chi^2_U}, \sqrt\frac{(n-1)s^2}{\chi^2_L} \right]](http://img.homeworklib.com/questions/e95a1680-3c43-11eb-91fb-e704fb8baab8.gif?x-oss-process=image/resize,w_560)
R-code
#h) 95% confidence interval of standard deviation for machine
2
alpha<-0.05
#get the lower tail critical value
chil<-qchisq(alpha/2,df=n2-1)
#get the upper tail critical value
chiu<-qchisq(1-alpha/2,df=n2-1)
#get the lower value of CI
lci2<-sqrt((n2-1)*v2/chiu)
#get the upper value of CI
uci2<-sqrt((n2-1)*v2/chil)
print(paste("The 95% confidence interval for the standard deviation
of machine 2 is [",round(lci2,4),",",round(uci2,4),"]",sep=""))
# output is

IJ) Machine 1 has a larger variance ( 0.0489) in the weights of nags compared to machine 2 (0.0059).
Machine 1 also has a larger confidence interval for standard deviation:
R- code
print(paste("length of CI of SD of machine 1 is ",
round(sqrt(uci1) - sqrt(lci1),4)))
print(paste("length of CI of SD of machine 2 is ", round(uci2 -
lci2,4)))
#output

Hence machine 1 provides a greater opportunities for improvement.
Please hit like button
Add Answer to:
1. The variance in a production process is an
important measure of the quality of the...
The variance in a production process is an important measure of the quality of the process....
 The variance in a production process is an important measure of the quality of the process. A large variance often signals an opportunity for improvement in the process by finding ways to reduce the process variance Machine 1 Machinc 2 2.95 3.45 3.50 3.75 3.48 3.26 3.33 3.20 3.16 3.20 3.22 3.38 3.90 3.36 3.25 3.28 3.20 3.22 2.98 3.45 3.70 3.34 3.18 3.35 3.12 3.22 3.30 3.34 3.28 3.29 3.25 3.30 3.27 3.38 3.34 3.35 3.19 3.35 3.05 3.36...
The variance in a production process is an important measure of the quality of the process. A large variance often signals an opportunity for improvement in the process by finding ways to reduce the process variance Machine 1 Machinc 2 2.95 3.45 3.50 3.75 3.48 3.26 3.33 3.20 3.16 3.20 3.22 3.38 3.90 3.36 3.25 3.28 3.20 3.22 2.98 3.45 3.70 3.34 3.18 3.35 3.12 3.22 3.30 3.34 3.28 3.29 3.25 3.30 3.27 3.38 3.34 3.35 3.19 3.35 3.05 3.36...
pH is a measure of acidity that winemakers must watch. A "healthy wine" should have a...
pH is a measure of acidity that winemakers must watch. A "healthy wine" should have a pH in the range 3.1 to 3.7. The target standard deviation is σ = 0.50 (i.e., σ2 = 0.25). The pH measurements for a sample of 16 bottles of wine are shown below. At α = .05 in a two-tailed test, is the sample variance either too high or too low? 3.48 3.54 3.27 3.46 3.45 3.46 3.33 3.60 3.46 3.55 3.54 3.43 3.50...
Show work if possible please An experiment has a single factor with five groups and five values in each group. freedom....
 Show work if possible please
An experiment has a single factor with five groups and five values in each group. freedom. In determining the total variation, there are: determining the among-group variation, there are 4 degrees freedom. In determining the within-group variation, there are 20 degrees of degrees of freedom. Also, note that SSA 96, SsW 120, SST = 216, MSA 24. MSW 6, and FSTAT 4. Complete parts (a) through (d). Click here to view page 1 of the...
Show work if possible please
An experiment has a single factor with five groups and five values in each group. freedom. In determining the total variation, there are: determining the among-group variation, there are 4 degrees freedom. In determining the within-group variation, there are 20 degrees of degrees of freedom. Also, note that SSA 96, SsW 120, SST = 216, MSA 24. MSW 6, and FSTAT 4. Complete parts (a) through (d). Click here to view page 1 of the...
Nay programming languge is fine (MatLab, Octave, etc.) This is the whole document this last picture...
 Nay
programming languge is fine (MatLab, Octave, etc.)
This is the whole document this last picture i sent is the
first page
5. Write and save a function Sphere Area that accepts Radius as input argument, and returns SurfaceArea (4 tt r) as output argument. Paste the function code below. Paste code here 6. Validate your Sphere Area function from the command line, checking the results against hand calculations. Paste the command line code and results below. 7. Design an...
Nay
programming languge is fine (MatLab, Octave, etc.)
This is the whole document this last picture i sent is the
first page
5. Write and save a function Sphere Area that accepts Radius as input argument, and returns SurfaceArea (4 tt r) as output argument. Paste the function code below. Paste code here 6. Validate your Sphere Area function from the command line, checking the results against hand calculations. Paste the command line code and results below. 7. Design an...
The median wage for economics degree holders is determined by the following equation: log( wage) = Be...
 The median wage for economics degree holders is determined by the following equation: log( wage) = Be + B educ + B, exper+ B temure + B.age+ B married + u where educ is the level of education measured in years, exper is the job-market experience in years, tenure is the time spend with the current company in years, age is the age in years and married is a dummy variable indicating if a person is married. 935 reg Iwage...
The median wage for economics degree holders is determined by the following equation: log( wage) = Be + B educ + B, exper+ B temure + B.age+ B married + u where educ is the level of education measured in years, exper is the job-market experience in years, tenure is the time spend with the current company in years, age is the age in years and married is a dummy variable indicating if a person is married. 935 reg Iwage...
bug fix of python here's the program: import binascii file = open("nibbles.txt", "r") count = 1...
bug fix of python here's the program: import binascii file = open("nibbles.txt", "r") count = 1 bytes = "" message = "" for i, line in enumerate(file): startIndex = line.index('(') endIndex = line.index(')') co = line[startIndex:endIndex+1] # (-1.35, 2.30) coordinates = line[startIndex+1:endIndex] # -1.35, 2.30 comma = coordinates.index(',') iVoltage = coordinates[0:comma] iv = float(iVoltage) qVoltage = coordinates[comma+2:] qv = float(qVoltage) if iv >= 0 and iv <= 2 and qv >= 0 and qv <= 2: point = "1101"...
REGRESSION 2 • reg bught cigs faminc male Source SS df MS = = Model Residual...
 REGRESSION 2 • reg bught cigs faminc male Source SS df MS = = Model Residual 20477.12 554134.6 3 6825.70666 1,384 400.386272 Number of obs F(3, 1384) Prob > R-squared Adj R-squared Root MSE 1,388 17.05 0.0000 0.0356 0.0335 20.01 - Total 574611.72 1,387 414.283864 bwght Coef. Std. Err. Piti (95Conf. Intervall cigs famine male _cons -.4610457 0913378 .09687980291453 3.113968 1.076396 115.2277 1.20788 -5.050.000 3.32 0.001 2.89 0.004 95.400.000 -.6402212 .0397062 1.002423 112.8582 - 2818702 .1540535 5.225513 117.5972 f) Conduct...
REGRESSION 2 • reg bught cigs faminc male Source SS df MS = = Model Residual 20477.12 554134.6 3 6825.70666 1,384 400.386272 Number of obs F(3, 1384) Prob > R-squared Adj R-squared Root MSE 1,388 17.05 0.0000 0.0356 0.0335 20.01 - Total 574611.72 1,387 414.283864 bwght Coef. Std. Err. Piti (95Conf. Intervall cigs famine male _cons -.4610457 0913378 .09687980291453 3.113968 1.076396 115.2277 1.20788 -5.050.000 3.32 0.001 2.89 0.004 95.400.000 -.6402212 .0397062 1.002423 112.8582 - 2818702 .1540535 5.225513 117.5972 f) Conduct...
3. Which group (family member/race/ethnicity) had the highest mean score for “Global self-worth?”...
 3. Which group (family member/race/ethnicity) had the
highest mean score for “Global self-worth?”
6. Should the null hypothesis be rejected for the
difference referred to in Question 3? If so, at what probability
level should it be rejected?
7. Were there any statistically significant
differences in adolescents’ self-esteem scores across racial and
ethnic categories for any of the measures of self-esteem? Explain
your answer.
Backgrona Nete A onc-way ANOVA was run for cach row in the table in the excert....
3. Which group (family member/race/ethnicity) had the
highest mean score for “Global self-worth?”
6. Should the null hypothesis be rejected for the
difference referred to in Question 3? If so, at what probability
level should it be rejected?
7. Were there any statistically significant
differences in adolescents’ self-esteem scores across racial and
ethnic categories for any of the measures of self-esteem? Explain
your answer.
Backgrona Nete A onc-way ANOVA was run for cach row in the table in the excert....
3. Which group (family member/race/ethnicity) had the highest mean score for “Global self-worth?”...
 3. Which group (family member/race/ethnicity) had the highest
mean score for “Global self-worth?”
4. Which group (family member, race/ethnicity) had the lowest
mean score for “Global self-worth?”
5. Should the mean differences for Fathers in “Physical
appearance” be declared statistically significant? Why or why
not?
6. Should the null hypothesis be rejected for the difference
referred to in Question 3? If so, at what probability level should
it be rejected?
7. Were there any statistically significant differences in
adolescents’ self-esteem...
3. Which group (family member/race/ethnicity) had the highest
mean score for “Global self-worth?”
4. Which group (family member, race/ethnicity) had the lowest
mean score for “Global self-worth?”
5. Should the mean differences for Fathers in “Physical
appearance” be declared statistically significant? Why or why
not?
6. Should the null hypothesis be rejected for the difference
referred to in Question 3? If so, at what probability level should
it be rejected?
7. Were there any statistically significant differences in
adolescents’ self-esteem...
Here 5.0000080853276E-7 after Background: The butterfat content of random samples of Guernsey, Holstein and Jersey cows...
Here 5.0000080853276E-7 after Background: The butterfat content of random samples of Guernsey, Holstein and Jersey cows are provided below. Each data value represents the percentage butterfat. Source: Sokal, R. R. and Rohlf, F. J. (1994) Biometry. W. H. Freeman, New York, third edition. Directions: Perform an analysis of variance (ANOVA) to determine if the differences in the percentage butterfat of the different breeds of cows is statistically significant. Click on the Data button below to display the data. Copy the...
 The variance in a production process is an important measure of the quality of the process. A large variance often signals an opportunity for improvement in the process by finding ways to reduce the process variance Machine 1 Machinc 2 2.95 3.45 3.50 3.75 3.48 3.26 3.33 3.20 3.16 3.20 3.22 3.38 3.90 3.36 3.25 3.28 3.20 3.22 2.98 3.45 3.70 3.34 3.18 3.35 3.12 3.22 3.30 3.34 3.28 3.29 3.25 3.30 3.27 3.38 3.34 3.35 3.19 3.35 3.05 3.36...
The variance in a production process is an important measure of the quality of the process. A large variance often signals an opportunity for improvement in the process by finding ways to reduce the process variance Machine 1 Machinc 2 2.95 3.45 3.50 3.75 3.48 3.26 3.33 3.20 3.16 3.20 3.22 3.38 3.90 3.36 3.25 3.28 3.20 3.22 2.98 3.45 3.70 3.34 3.18 3.35 3.12 3.22 3.30 3.34 3.28 3.29 3.25 3.30 3.27 3.38 3.34 3.35 3.19 3.35 3.05 3.36...
 Show work if possible please
An experiment has a single factor with five groups and five values in each group. freedom. In determining the total variation, there are: determining the among-group variation, there are 4 degrees freedom. In determining the within-group variation, there are 20 degrees of degrees of freedom. Also, note that SSA 96, SsW 120, SST = 216, MSA 24. MSW 6, and FSTAT 4. Complete parts (a) through (d). Click here to view page 1 of the...
Show work if possible please
An experiment has a single factor with five groups and five values in each group. freedom. In determining the total variation, there are: determining the among-group variation, there are 4 degrees freedom. In determining the within-group variation, there are 20 degrees of degrees of freedom. Also, note that SSA 96, SsW 120, SST = 216, MSA 24. MSW 6, and FSTAT 4. Complete parts (a) through (d). Click here to view page 1 of the...
 Nay
programming languge is fine (MatLab, Octave, etc.)
This is the whole document this last picture i sent is the
first page
5. Write and save a function Sphere Area that accepts Radius as input argument, and returns SurfaceArea (4 tt r) as output argument. Paste the function code below. Paste code here 6. Validate your Sphere Area function from the command line, checking the results against hand calculations. Paste the command line code and results below. 7. Design an...
Nay
programming languge is fine (MatLab, Octave, etc.)
This is the whole document this last picture i sent is the
first page
5. Write and save a function Sphere Area that accepts Radius as input argument, and returns SurfaceArea (4 tt r) as output argument. Paste the function code below. Paste code here 6. Validate your Sphere Area function from the command line, checking the results against hand calculations. Paste the command line code and results below. 7. Design an...
 The median wage for economics degree holders is determined by the following equation: log( wage) = Be + B educ + B, exper+ B temure + B.age+ B married + u where educ is the level of education measured in years, exper is the job-market experience in years, tenure is the time spend with the current company in years, age is the age in years and married is a dummy variable indicating if a person is married. 935 reg Iwage...
The median wage for economics degree holders is determined by the following equation: log( wage) = Be + B educ + B, exper+ B temure + B.age+ B married + u where educ is the level of education measured in years, exper is the job-market experience in years, tenure is the time spend with the current company in years, age is the age in years and married is a dummy variable indicating if a person is married. 935 reg Iwage...
 REGRESSION 2 • reg bught cigs faminc male Source SS df MS = = Model Residual 20477.12 554134.6 3 6825.70666 1,384 400.386272 Number of obs F(3, 1384) Prob > R-squared Adj R-squared Root MSE 1,388 17.05 0.0000 0.0356 0.0335 20.01 - Total 574611.72 1,387 414.283864 bwght Coef. Std. Err. Piti (95Conf. Intervall cigs famine male _cons -.4610457 0913378 .09687980291453 3.113968 1.076396 115.2277 1.20788 -5.050.000 3.32 0.001 2.89 0.004 95.400.000 -.6402212 .0397062 1.002423 112.8582 - 2818702 .1540535 5.225513 117.5972 f) Conduct...
REGRESSION 2 • reg bught cigs faminc male Source SS df MS = = Model Residual 20477.12 554134.6 3 6825.70666 1,384 400.386272 Number of obs F(3, 1384) Prob > R-squared Adj R-squared Root MSE 1,388 17.05 0.0000 0.0356 0.0335 20.01 - Total 574611.72 1,387 414.283864 bwght Coef. Std. Err. Piti (95Conf. Intervall cigs famine male _cons -.4610457 0913378 .09687980291453 3.113968 1.076396 115.2277 1.20788 -5.050.000 3.32 0.001 2.89 0.004 95.400.000 -.6402212 .0397062 1.002423 112.8582 - 2818702 .1540535 5.225513 117.5972 f) Conduct...
 3. Which group (family member/race/ethnicity) had the
highest mean score for “Global self-worth?”
6. Should the null hypothesis be rejected for the
difference referred to in Question 3? If so, at what probability
level should it be rejected?
7. Were there any statistically significant
differences in adolescents’ self-esteem scores across racial and
ethnic categories for any of the measures of self-esteem? Explain
your answer.
Backgrona Nete A onc-way ANOVA was run for cach row in the table in the excert....
3. Which group (family member/race/ethnicity) had the
highest mean score for “Global self-worth?”
6. Should the null hypothesis be rejected for the
difference referred to in Question 3? If so, at what probability
level should it be rejected?
7. Were there any statistically significant
differences in adolescents’ self-esteem scores across racial and
ethnic categories for any of the measures of self-esteem? Explain
your answer.
Backgrona Nete A onc-way ANOVA was run for cach row in the table in the excert....
 3. Which group (family member/race/ethnicity) had the highest
mean score for “Global self-worth?”
4. Which group (family member, race/ethnicity) had the lowest
mean score for “Global self-worth?”
5. Should the mean differences for Fathers in “Physical
appearance” be declared statistically significant? Why or why
not?
6. Should the null hypothesis be rejected for the difference
referred to in Question 3? If so, at what probability level should
it be rejected?
7. Were there any statistically significant differences in
adolescents’ self-esteem...
3. Which group (family member/race/ethnicity) had the highest
mean score for “Global self-worth?”
4. Which group (family member, race/ethnicity) had the lowest
mean score for “Global self-worth?”
5. Should the mean differences for Fathers in “Physical
appearance” be declared statistically significant? Why or why
not?
6. Should the null hypothesis be rejected for the difference
referred to in Question 3? If so, at what probability level should
it be rejected?
7. Were there any statistically significant differences in
adolescents’ self-esteem...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago