
Homework Answers
(a) Here we are to test

where p is the proportion of the persons in the sample with blonde hair. It is evident

Now the probability of type I error is given by

We calculate this probability using R.
R CODE:
comb = function(n, x)
{
factorial(n) / factorial(n-x) / factorial(x)
}
comb(18,15)*(0.66^15)*((1-0.66)^(18-15))
R OUTPUT:
0.06299208
Hence the probability of type I error is 0.06299208
In this context, type I error is the error commited in rejecting the hypothesis that the proportion of people with blonde hair in the given population is 0.66 even when it is true and the probability of doing this is 0.06299208.
(b)
Given the actual percentage of population with blonde hair is 72%.
(a) Here we are to test
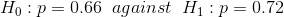
where p is the proportion of the persons in the sample with blonde hair. It is evident
Now the probability of type II error is given by

We calculate this probability using R.
R CODE:
comb = function(n, x)
{
factorial(n) / factorial(n-x) / factorial(x)
}
1-(comb(18,15)*(0.72^15)*((1-0.72)^(18-15)))
R OUTPUT:
0.8702368
In this context, type II error is the error commited in accepting the hypothesis that the proportion of people with blonde hair in the given population is 0.66 even when it is false and the probability of doing this is 0.8702368.
Hopefully this will help you. If you are satisfied with the answer, give it a like. In case of any query, do comment. Thanks.
Add Answer to:
please answer (a) and (b) and if possible please use R Studio
when solving
Question 2...
6. (30 points) It was traditionally accepted that you could get 120 calories on average from a serving of vanilla yogurt. In 2016 a new diet guide claims that you will get more than calories on a...
 6. (30 points) It was traditionally accepted that you could get 120 calories on average from a serving of vanilla yogurt. In 2016 a new diet guide claims that you will get more than calories on average. Is there any compelling evidence to support this clairm data provided in problem 1 to conduct a test, with a 0.05. Assume the population is normally distributed. (a) (5 points) Please write appropriate hypotheses. (b) (5 points) Compute the test statistic. (c) (5...
6. (30 points) It was traditionally accepted that you could get 120 calories on average from a serving of vanilla yogurt. In 2016 a new diet guide claims that you will get more than calories on average. Is there any compelling evidence to support this clairm data provided in problem 1 to conduct a test, with a 0.05. Assume the population is normally distributed. (a) (5 points) Please write appropriate hypotheses. (b) (5 points) Compute the test statistic. (c) (5...
Really short question! Please help me to solve ONLY part(b) with R code. Thank you! Problem...
 Really short question! Please help me to solve ONLY part(b)
with R code. Thank you!
Problem 4 [26 points] (Section 2.4): Consider a one-sample z-test (known variance) with hypotheses: Ho: μ lo vs H, μ *Ho. The probability of Type II error can be written in the form |ß D(%2_Jnd)-0(-%2_Jnd) where Φ㈠ is the CDF of N(0,1), d Isyo, and δ is the difference between the true mean and the mean under Ho (a) [10 points] Based on the fact...
Really short question! Please help me to solve ONLY part(b)
with R code. Thank you!
Problem 4 [26 points] (Section 2.4): Consider a one-sample z-test (known variance) with hypotheses: Ho: μ lo vs H, μ *Ho. The probability of Type II error can be written in the form |ß D(%2_Jnd)-0(-%2_Jnd) where Φ㈠ is the CDF of N(0,1), d Isyo, and δ is the difference between the true mean and the mean under Ho (a) [10 points] Based on the fact...
To test Ho: p=0.35 versus Hy:p>0.35, a simple random sample of n = 200 individuals is obtained and x = 69 successes are observed. (a) What does it mean to make a Type Il error for this test? (b) If the researcher decides to test this hypothesis at the a =
 To test Ho: p=0.35 versus Hy:p>0.35, a simple random sample of n = 200 individuals is obtained and x = 69 successes are observed. (a) What does it mean to make a Type Il error for this test? (b) If the researcher decides to test this hypothesis at the a = 0.01 level of significance, compute the probability of making a Type II error, B, if the true population proportion is 0.38. What is the power of the test? (c)...
To test Ho: p=0.35 versus Hy:p>0.35, a simple random sample of n = 200 individuals is obtained and x = 69 successes are observed. (a) What does it mean to make a Type Il error for this test? (b) If the researcher decides to test this hypothesis at the a = 0.01 level of significance, compute the probability of making a Type II error, B, if the true population proportion is 0.38. What is the power of the test? (c)...
I would like the whole Question done on r studio with the R Code. 1. In...
 I would like the whole Question done on r studio with
the R Code.
1. In this question we will evaluate type I and type II error probabilities for one-sided tests. We will consider normally distributed data, with unit variance and independent obervations. We will use Ho : μ-0 for the null and H1 : μ-1 for the alternative, unless otherwise stated. (a) Suppose we have n-6 observationsx. What is the sampling distribution of the (10 marks) sample mean (that...
I would like the whole Question done on r studio with
the R Code.
1. In this question we will evaluate type I and type II error probabilities for one-sided tests. We will consider normally distributed data, with unit variance and independent obervations. We will use Ho : μ-0 for the null and H1 : μ-1 for the alternative, unless otherwise stated. (a) Suppose we have n-6 observationsx. What is the sampling distribution of the (10 marks) sample mean (that...
1. An automobile tire manufacturer would like to claim that the tread life (in miles) of...
 1. An automobile tire manufacturer would like to claim that the tread life (in miles) of a certain type of tire is greater than 30,000 miles. Assuming a normal population with 1500 miles answer the following for a test of the hypotheses Ho :-30,000 versus Ha : μ > 30,000 a) Ifa -.01 specify the rejection region as an inequality involving the value of the test statistic b) Based on a sample size of n 25, the corresponding rejection region...
1. An automobile tire manufacturer would like to claim that the tread life (in miles) of a certain type of tire is greater than 30,000 miles. Assuming a normal population with 1500 miles answer the following for a test of the hypotheses Ho :-30,000 versus Ha : μ > 30,000 a) Ifa -.01 specify the rejection region as an inequality involving the value of the test statistic b) Based on a sample size of n 25, the corresponding rejection region...
Two different companies have applied to provide cable television service in a certain region. Let p...
 Two different companies have applied to provide cable television service in a certain region. Let p denote the proportion of all potential subscribers who favor the first company over the second. Consider testing H0: p = .5versus Ha: p ≠ .5 based on a random sample of 25 individuals. Let X denote the number in the sample who favor the first company and x represent the observed value of X. a. Which of the following rejection regions is most appropriate...
Two different companies have applied to provide cable television service in a certain region. Let p denote the proportion of all potential subscribers who favor the first company over the second. Consider testing H0: p = .5versus Ha: p ≠ .5 based on a random sample of 25 individuals. Let X denote the number in the sample who favor the first company and x represent the observed value of X. a. Which of the following rejection regions is most appropriate...
You may need to use the appropriate appendix table or technology to answer this question. A...
You may need to use the appropriate appendix table or technology to answer this question. A consumer research group is interested in testing an automobile manufacturer's claim that a new economy model will travel at least 23 miles per gallon of gasoline (H0: μ ≥ 23). (a) With a 0.02 level of significance and a sample of 40 cars, what is the rejection rule based on the value of x̄ for the test to determine whether the manufacturer's claim should...
Please answer using R studio (1 point) Alzheimer's disease is a progressive disease of the brain....
 Please answer using R studio
(1 point) Alzheimer's disease is a progressive disease of the brain. An article published in 2006 was critical of the methodology used in studies of Alzheimer's treatments conducted prior to 2006. In a random sample of n = 31 Alzheimer's studies, the quality of the methodology was measured on the Wong scale with scores ranging from 9 (low quality) to 27 (high quality) for each study. The data is provided below. data can be copied...
Please answer using R studio
(1 point) Alzheimer's disease is a progressive disease of the brain. An article published in 2006 was critical of the methodology used in studies of Alzheimer's treatments conducted prior to 2006. In a random sample of n = 31 Alzheimer's studies, the quality of the methodology was measured on the Wong scale with scores ranging from 9 (low quality) to 27 (high quality) for each study. The data is provided below. data can be copied...
Really short question! Please help me to solve part(b), also need the R code, thank you!...
 Really short question! Please help me to solve part(b), also
need the R code, thank you!
Problem 4 [26 points] (Section 2.4): Consider a one-sample z-test (known variance) with hypotheses: Ho: μ lo vs H, μ μο. a/2 where φ(.)Is the CDF of N(0,1), d-layo, and δ is the difference between the true mean and the mean under Ho (a) [10 points] Based on the fact that φ(x) [pdf of N(0,1)] is a decreasing function in x when x> 0,...
Really short question! Please help me to solve part(b), also
need the R code, thank you!
Problem 4 [26 points] (Section 2.4): Consider a one-sample z-test (known variance) with hypotheses: Ho: μ lo vs H, μ μο. a/2 where φ(.)Is the CDF of N(0,1), d-layo, and δ is the difference between the true mean and the mean under Ho (a) [10 points] Based on the fact that φ(x) [pdf of N(0,1)] is a decreasing function in x when x> 0,...
please give correct and answer all question.. this is revision question... 14. Which of the following...
 please give correct and answer all question.. this is revision
question...
14. Which of the following statistical tests is BEST TO normally distributed data? in statistical tests is BEST to use for comparing two samples A. Independent sample t-test B.Mann-Whitney test C. Regression analysis D. Logistic regression analysis 15. Which of the following is NOT related to central limit theoret? sample size is large. bution of sample mean, x is approximately normal regardless of Xin the population 9. The mean...
please give correct and answer all question.. this is revision
question...
14. Which of the following statistical tests is BEST TO normally distributed data? in statistical tests is BEST to use for comparing two samples A. Independent sample t-test B.Mann-Whitney test C. Regression analysis D. Logistic regression analysis 15. Which of the following is NOT related to central limit theoret? sample size is large. bution of sample mean, x is approximately normal regardless of Xin the population 9. The mean...
 6. (30 points) It was traditionally accepted that you could get 120 calories on average from a serving of vanilla yogurt. In 2016 a new diet guide claims that you will get more than calories on average. Is there any compelling evidence to support this clairm data provided in problem 1 to conduct a test, with a 0.05. Assume the population is normally distributed. (a) (5 points) Please write appropriate hypotheses. (b) (5 points) Compute the test statistic. (c) (5...
6. (30 points) It was traditionally accepted that you could get 120 calories on average from a serving of vanilla yogurt. In 2016 a new diet guide claims that you will get more than calories on average. Is there any compelling evidence to support this clairm data provided in problem 1 to conduct a test, with a 0.05. Assume the population is normally distributed. (a) (5 points) Please write appropriate hypotheses. (b) (5 points) Compute the test statistic. (c) (5...
 Really short question! Please help me to solve ONLY part(b)
with R code. Thank you!
Problem 4 [26 points] (Section 2.4): Consider a one-sample z-test (known variance) with hypotheses: Ho: μ lo vs H, μ *Ho. The probability of Type II error can be written in the form |ß D(%2_Jnd)-0(-%2_Jnd) where Φ㈠ is the CDF of N(0,1), d Isyo, and δ is the difference between the true mean and the mean under Ho (a) [10 points] Based on the fact...
Really short question! Please help me to solve ONLY part(b)
with R code. Thank you!
Problem 4 [26 points] (Section 2.4): Consider a one-sample z-test (known variance) with hypotheses: Ho: μ lo vs H, μ *Ho. The probability of Type II error can be written in the form |ß D(%2_Jnd)-0(-%2_Jnd) where Φ㈠ is the CDF of N(0,1), d Isyo, and δ is the difference between the true mean and the mean under Ho (a) [10 points] Based on the fact...
 I would like the whole Question done on r studio with
the R Code.
1. In this question we will evaluate type I and type II error probabilities for one-sided tests. We will consider normally distributed data, with unit variance and independent obervations. We will use Ho : μ-0 for the null and H1 : μ-1 for the alternative, unless otherwise stated. (a) Suppose we have n-6 observationsx. What is the sampling distribution of the (10 marks) sample mean (that...
I would like the whole Question done on r studio with
the R Code.
1. In this question we will evaluate type I and type II error probabilities for one-sided tests. We will consider normally distributed data, with unit variance and independent obervations. We will use Ho : μ-0 for the null and H1 : μ-1 for the alternative, unless otherwise stated. (a) Suppose we have n-6 observationsx. What is the sampling distribution of the (10 marks) sample mean (that...
 1. An automobile tire manufacturer would like to claim that the tread life (in miles) of a certain type of tire is greater than 30,000 miles. Assuming a normal population with 1500 miles answer the following for a test of the hypotheses Ho :-30,000 versus Ha : μ > 30,000 a) Ifa -.01 specify the rejection region as an inequality involving the value of the test statistic b) Based on a sample size of n 25, the corresponding rejection region...
1. An automobile tire manufacturer would like to claim that the tread life (in miles) of a certain type of tire is greater than 30,000 miles. Assuming a normal population with 1500 miles answer the following for a test of the hypotheses Ho :-30,000 versus Ha : μ > 30,000 a) Ifa -.01 specify the rejection region as an inequality involving the value of the test statistic b) Based on a sample size of n 25, the corresponding rejection region...
 Two different companies have applied to provide cable television service in a certain region. Let p denote the proportion of all potential subscribers who favor the first company over the second. Consider testing H0: p = .5versus Ha: p ≠ .5 based on a random sample of 25 individuals. Let X denote the number in the sample who favor the first company and x represent the observed value of X. a. Which of the following rejection regions is most appropriate...
Two different companies have applied to provide cable television service in a certain region. Let p denote the proportion of all potential subscribers who favor the first company over the second. Consider testing H0: p = .5versus Ha: p ≠ .5 based on a random sample of 25 individuals. Let X denote the number in the sample who favor the first company and x represent the observed value of X. a. Which of the following rejection regions is most appropriate...
 Please answer using R studio
(1 point) Alzheimer's disease is a progressive disease of the brain. An article published in 2006 was critical of the methodology used in studies of Alzheimer's treatments conducted prior to 2006. In a random sample of n = 31 Alzheimer's studies, the quality of the methodology was measured on the Wong scale with scores ranging from 9 (low quality) to 27 (high quality) for each study. The data is provided below. data can be copied...
Please answer using R studio
(1 point) Alzheimer's disease is a progressive disease of the brain. An article published in 2006 was critical of the methodology used in studies of Alzheimer's treatments conducted prior to 2006. In a random sample of n = 31 Alzheimer's studies, the quality of the methodology was measured on the Wong scale with scores ranging from 9 (low quality) to 27 (high quality) for each study. The data is provided below. data can be copied...
 Really short question! Please help me to solve part(b), also
need the R code, thank you!
Problem 4 [26 points] (Section 2.4): Consider a one-sample z-test (known variance) with hypotheses: Ho: μ lo vs H, μ μο. a/2 where φ(.)Is the CDF of N(0,1), d-layo, and δ is the difference between the true mean and the mean under Ho (a) [10 points] Based on the fact that φ(x) [pdf of N(0,1)] is a decreasing function in x when x> 0,...
Really short question! Please help me to solve part(b), also
need the R code, thank you!
Problem 4 [26 points] (Section 2.4): Consider a one-sample z-test (known variance) with hypotheses: Ho: μ lo vs H, μ μο. a/2 where φ(.)Is the CDF of N(0,1), d-layo, and δ is the difference between the true mean and the mean under Ho (a) [10 points] Based on the fact that φ(x) [pdf of N(0,1)] is a decreasing function in x when x> 0,...
 please give correct and answer all question.. this is revision
question...
14. Which of the following statistical tests is BEST TO normally distributed data? in statistical tests is BEST to use for comparing two samples A. Independent sample t-test B.Mann-Whitney test C. Regression analysis D. Logistic regression analysis 15. Which of the following is NOT related to central limit theoret? sample size is large. bution of sample mean, x is approximately normal regardless of Xin the population 9. The mean...
please give correct and answer all question.. this is revision
question...
14. Which of the following statistical tests is BEST TO normally distributed data? in statistical tests is BEST to use for comparing two samples A. Independent sample t-test B.Mann-Whitney test C. Regression analysis D. Logistic regression analysis 15. Which of the following is NOT related to central limit theoret? sample size is large. bution of sample mean, x is approximately normal regardless of Xin the population 9. The mean...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago