How can I rewrite and better understand the code since it is not working. Thank you...
How can I rewrite and better understand the code since it is not working. Thank you for helping me!! It means a lot :)
CODE:
import numpy as np
def coeff(x):
X = x[:,0]
Y = x[:,1]
if len(X)>=11:
L = 10
else:
L = len(X)-1
nm = np.zeros((L,1))
for i in range(1,L):
fit = np.polyfit(X,Y,i)
val = np.polyval(fit,X)
nm[i-1,0] = np.linalg.norm(Y-val)
I = nm.argmin()
coeff = np.polyfit(X,Y,I)
print(coeff)
Homework Answers
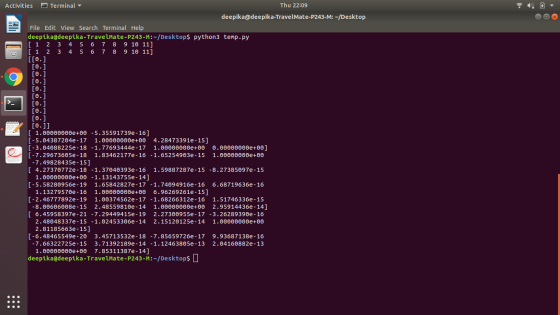
I made a small modification in the program and got that as output. Is it the thing that you what otherwise you can specify the requirements so that I will modify according to that.
If you have any doubts please comment and please don't dislike.
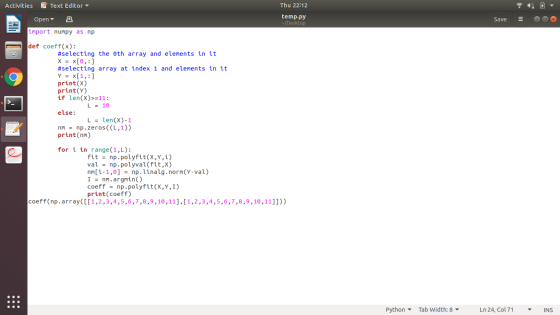
import numpy as np
def coeff(x):
#selecting the 0th array and elements in it
X = x[0,:]
#selecting array at index 1 and elements in it
Y = x[1,:]
print(X)
print(Y)
if len(X)>=11:
L = 10
else:
L = len(X)-1
nm = np.zeros((L,1))
print(nm)
for i in range(1,L):
fit = np.polyfit(X,Y,i)
val = np.polyval(fit,X)
nm[i-1,0] =
np.linalg.norm(Y-val)
I = nm.argmin()
coeff = np.polyfit(X,Y,I)
print(coeff)
coeff(np.array([[1,2,3,4,5,6,7,8,9,10,11],[1,2,3,4,5,6,7,8,9,10,11]]))
Add Answer to:
How can I rewrite and better understand the code since it is not
working. Thank you...
Python, I need help with glob. I have a lot of data text files and want...
Python, I need help with glob. I have a lot of data text files and want to order them. However glob makes it in the wrong order. Have: data00120.txt data00022.txt data00045.txt etc Want: data00000.txt data00001.txt data00002.txt etc Code piece: def last_9chars(x): return(x[-9:]) files = sorted(glob.glob('data*.txt'),key = last_9chars) whole code: import numpy as np import matplotlib.pyplot as plt import glob import sys import re from prettytable import PrettyTable def last_9chars(x): return(x[-9:]) files = sorted(glob.glob('data*.txt'),key = last_9chars) x = PrettyTable() x.field_names =...
Please help! I am trying to make a convolution but i am receiving a syntax error....
Please help! I am trying to make a convolution but i am receiving a syntax error. If anyone can help with how to do the convolution it would be much appreciated! This first part is the main program. import numpy as np from numpy import * import pylab as pl import wave import struct from my_conv import myconv #import scipy.signal as signal ##-------------------------------------------------------------------- ## read the input wave file "speech.wav" f = wave.open("speech.wav", "rb") params = f.getparams() nchannels, sampwidth, framerate,...
(Please help me with Coding in Python3) AVLTree complete the following implementation of the balanced (AVL)...
(Please help me with Coding in Python3) AVLTree complete the following implementation of the balanced (AVL) binary search tree. Note that you should not be implementing the map-based API described in the plain (unbalanced) BSTree notebook — i.e., nodes in the AVLTree will only contain a single value. class AVLTree: class Node: def __init__(self, val, left=None, right=None): self.val = val self.left = left self.right = right def rotate_right(self): n = self.left self.val, n.val = n.val, self.val self.left, n.left, self.right, n.right...
Undecimal to decimal&decimal to undecimal #Your code here Thank you! Binary-to-Decimal In a previous lab, we...
 Undecimal to decimal&decimal to undecimal
#Your code here
Thank you!
Binary-to-Decimal In a previous lab, we considered converting a byte string to decimal. What about converting a binary string of arbitrary length to decimal? Given a binary string of an arbitrarily length k, bk-1....bi .box the decimal number can be computed by the formula 20 .bo +21.b, + ... + 2k-1. bx-1- In mathematics, we use the summation notation to write the above formula: k- 2.b; i=0) In a program,...
Undecimal to decimal&decimal to undecimal
#Your code here
Thank you!
Binary-to-Decimal In a previous lab, we considered converting a byte string to decimal. What about converting a binary string of arbitrary length to decimal? Given a binary string of an arbitrarily length k, bk-1....bi .box the decimal number can be computed by the formula 20 .bo +21.b, + ... + 2k-1. bx-1- In mathematics, we use the summation notation to write the above formula: k- 2.b; i=0) In a program,...
I need to rewrite this code without using lambda function using python. def three_x_y_at_one(x): result =...
I need to rewrite this code without using lambda function using python. def three_x_y_at_one(x): result = (3 * x *1) return result three_x_y_at_one(3) # 9 zero_to_four = list(range(0, 5)) def y_values_for_at_one(x_values): return list(map(lambda x : three_x_y_at_one(x), x_values)) -------> this is the function that I need to rewrite without using a lambda function . y_values_for_at_one(zero_to_four) # [0, 3, 6, 9, 12] Thanks
Python Merge Sort Adjust the following code so that you can create random lists of numbers of lengths 10, 15, and 20. You will run the merge sort 10 times for each length. Record the run time for the...
 Python Merge Sort
Adjust the following code so that you can create
random lists of numbers of lengths 10, 15,
and 20.
You will run the merge sort 10 times for each
length. Record the run time for the length and then calculate the
average time to sort.
Finally, compare the average run time for each length to the
average time for the Merge Sort.
--------------------------------------------
Initial python code:
import random
import time
def mergeSort(alist):
print("Splitting ",alist)
if len(alist)>1:
mid...
Python Merge Sort
Adjust the following code so that you can create
random lists of numbers of lengths 10, 15,
and 20.
You will run the merge sort 10 times for each
length. Record the run time for the length and then calculate the
average time to sort.
Finally, compare the average run time for each length to the
average time for the Merge Sort.
--------------------------------------------
Initial python code:
import random
import time
def mergeSort(alist):
print("Splitting ",alist)
if len(alist)>1:
mid...
How can i rewrite this code?( such as changing the statement) NOTE: do not add any...
How can i rewrite this code?( such as changing the statement) NOTE: do not add any import other than : import java.util.ArrayList; import java.util.Collection;(collection not collections) import java.util.List; import java.util.Set; import java.util.TreeSet; import java.util.HashSet; code: public static long sum(Collection values) { if(values==null || values.size()<1) return 0; int sum = 0; for (Integer i: values) sum = sum+i; return sum; }
########### Homework 20 ################################## ################################################### #### Rewrite this code in 'class mode' : define the class...
########### Homework 20 ################################## ################################################### #### Rewrite this code in 'class mode' : define the class and so on.... #### If you can - try make a clicked button 'blue'. #### (Only if you can.) from tkinter import * abc = 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' def callback(x): label.configure(text = 'Button {} clicked'. format(abc[x])) root = Tk() label = Label() label.grid(row = 1, column = 0, columnspan = 26) buttons = [0]*26 ##create a list to hold 26 buttons for i in range(26): buttons[i]...
Throughout this script, can you provide helpful comments about how each function works in the script...
Throughout this script, can you provide helpful comments about how each function works in the script plus it's significance to the alignment process. Also are there any errors in this script or a way to improve this script? Any help would be appreciated. Thank you. THIS IS A PYTHON CODE AND IS IN IT'S FORMAT _ ITS CLEAR! #!/usr/bin/env python # file=input("Please provide fasta file with 2 sequences:") match=float(input('What is the match score?:')) missmatch=float(input('What is the missmatch score?:')) gap=float(input('What is...
This is my code: import numpy as np import pandas as pd import sys from keras.models...
This is my code: import numpy as np import pandas as pd import sys from keras.models import Sequential from keras.layers import Dense from sklearn.preprocessing import StandardScaler from keras.layers.normalization import BatchNormalization from keras.layers import Dropout file_full=pd.read_csv("/Users/anwer/Desktop/copy/FULL.csv") file_bottom=pd.read_csv("/Users/anwer/Desktop/copy/bottom.csv") train=[] train_targets=[] test=[] test_targets=[] p=[] q=[] # We will generate train data using 50% of full data and 50% of bottom data. #is train target for labeling ? yes for train data train_df = file_full[:len(file_full)//2] labels=[ 0 for i in range(len(file_full)//2)] train_df=train_df.append(file_bottom[:len(file_bottom)//2]) for...
 Undecimal to decimal&decimal to undecimal
#Your code here
Thank you!
Binary-to-Decimal In a previous lab, we considered converting a byte string to decimal. What about converting a binary string of arbitrary length to decimal? Given a binary string of an arbitrarily length k, bk-1....bi .box the decimal number can be computed by the formula 20 .bo +21.b, + ... + 2k-1. bx-1- In mathematics, we use the summation notation to write the above formula: k- 2.b; i=0) In a program,...
Undecimal to decimal&decimal to undecimal
#Your code here
Thank you!
Binary-to-Decimal In a previous lab, we considered converting a byte string to decimal. What about converting a binary string of arbitrary length to decimal? Given a binary string of an arbitrarily length k, bk-1....bi .box the decimal number can be computed by the formula 20 .bo +21.b, + ... + 2k-1. bx-1- In mathematics, we use the summation notation to write the above formula: k- 2.b; i=0) In a program,...
 Python Merge Sort
Adjust the following code so that you can create
random lists of numbers of lengths 10, 15,
and 20.
You will run the merge sort 10 times for each
length. Record the run time for the length and then calculate the
average time to sort.
Finally, compare the average run time for each length to the
average time for the Merge Sort.
--------------------------------------------
Initial python code:
import random
import time
def mergeSort(alist):
print("Splitting ",alist)
if len(alist)>1:
mid...
Python Merge Sort
Adjust the following code so that you can create
random lists of numbers of lengths 10, 15,
and 20.
You will run the merge sort 10 times for each
length. Record the run time for the length and then calculate the
average time to sort.
Finally, compare the average run time for each length to the
average time for the Merge Sort.
--------------------------------------------
Initial python code:
import random
import time
def mergeSort(alist):
print("Splitting ",alist)
if len(alist)>1:
mid...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago