Alternative Classification How to Estimate Probabilities from Data? ( For continuous Attributes) And How to generate...
Alternative Classification
How to Estimate Probabilities from Data? ( For continuous Attributes)
And How to generate an ensemble of classifiers?
Homework Answers
aximum Likelihood Estimation (MLE)
Let P(H)=θ. θ, however, is
unknown and all we have is D (sequence of heads and
tails). So, what we can do to estimate θ is to choose its
value such that the data is most likely.
MLE Principle:
Find θ^ to maximize the likelihood of the data,
P(D∣θ):
θ^MLE=argmaxθP(D∣θ)
For the sequence of coin flips we can use the binomial
distribution to model
P(D∣θ):
P(D∣θ)=(nH+nTnH)θnH(1−θ)nT
Now,
θ^MLE=argmaxθ(nH+nTnH)θnH(1−θ)nT=argmaxθlog(nH+nTnH)+nH⋅log(θ)+nT⋅log(1−θ)=argmaxθnH⋅log(θ)+nT⋅log(1−θ)
We can now solve for θ by taking the derivative and equating it to zero. This results in
nHθ=nT1−θ⟹nH−nHθ=nTθ⟹θ=nHnH+nT
Check:
1≥θ≥0 (no constraints necessary)
- MLE gives the explanation of the data you observed.
- If n
is large and your model/distribution is correct (that is H
- includes the true model), then MLE finds the true parameters.
- But the MLE can overfit the data if n
- is small. It works well when n
- is large.
- If you do not have the correct model (and n
- is small) then MLE can be terribly wrong!
For example, suppose you observe H,H,H,H,H. What is θ^MLE?
Simple scenario: coin toss with prior knowledge
Assume you have a hunch that θ is close to
θ′=0.5. But your sample size is small, so you don't trust
your estimate.
Simple fix: Add
m imaginery throws that would result in θ′ (e.g.
θ=0.5). Add m Heads and m Tails to your
data.
θ^=nH+mnH+nT+2m
For large n, this is an insignificant change. For small
n, it incorporates your "prior belief" about what
θ should be.
Can we derive this formally?
The Bayesian Way
Model θ as a random variable, drawn
from a distribution P(θ). Note that θ is
not a random variable associated with an event in
a sample space. In frequentist statistics, this is forbidden. In
Bayesian statistics, this is allowed.
Now, we can look at
P(θ∣D)=P(D∣θ)P(θ)P(D)
(recall Bayes Rule!), where
- P(D∣θ)
is the likelihood of the data given the parameter(s) θ
- ,
- P(θ)
- is the prior distribution over the parameter(s) θ
- , and
- P(θ∣D)
- is the posterior distribution over the
parameter(s) θ
- .
Now, we can use the Beta distribution to model P(θ):P(θ)=θα−1(1−θ)β−1B(α,β)
where B(α,β)=Γ(α)Γ(β)Γ(α+β) is the normalization constant. Note that here we only need a distribution over a binary random variable. The multivariate generalization of the Beta distribution is the Dirichlet distribution.
Why using the Beta distribution?- it models probabilitis (θ
- )
- it is of the same distributional family as the binomial distribution (conjugate prior) →
- the math will turn out nicely:
P(θ∣D)∝P(D∣θ)P(θ)∝θnH+α−1(1−θ)nT+β−1
Note taht in general θ are the parameters of our model.
For the coin flipping scenario
θ=P(H).
So far, we have a distribution over θ. How can we get an
estimate for θ?
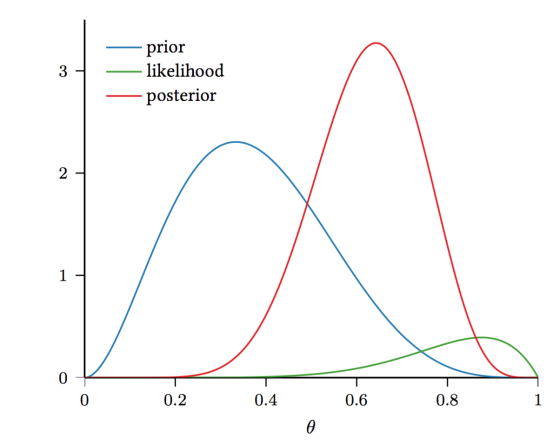
Maximum a Posteriori Probability Estimation (MAP)
For example, we can choose θ^ to be the most likely θ
given the
data.
MAP Principle:
Find θ^ that maximizes the posterior distribution
P(θ∣D):
θ^MAP=argmaxθP(θ∣D)=argmaxθlogP(D∣θ)+logP(θ)
For out coin flipping scenario, we get:
θ^MAP=argmaxθP(θ|Data)=argmaxθP(Data|θ)P(θ)P(Data)=argmaxθlog(P(Data|θ))+log(P(θ))=argmaxθnH⋅log(θ)+nT⋅log(1−θ)+(α−1)⋅log(θ)+(β−1)⋅log(1−θ)=argmaxθ(nH+α−1)⋅log(θ)+(nT+β−1)⋅log(1−θ)⟹θ^MAP=nH+α−1nH+nT+β+α−2(By Bayes rule)
- As n→∞
, θ^MAP→θ^MLE
- .
- MAP is a great estimator if prior belief exists and is accurate.
- If n
- is small, it can be very wrong if prior belief is wrong!
"True" Bayesian approach
Note that MAP is only one way to get an estimator for θ. There is much more information in P(θ∣D). So, instead of the maximum as we did with MAP, we can use the posterior mean (end even its variance).
θ^post_mean=E[θ,D]=∫θθP(θ∣D)dθ
For coin flipping, this can be computed as θ^post_mean=nH+αnH+α+nT+β.
Posterior Predictive Distribution
To make predictions using θ in our coin tossing example, we can use
P(heads∣D)=∫θP(heads,θ∣D)dθ=∫θP(heads∣θ,D)P(θ∣D)dθ=∫θθP(θ∣D)dθ
Here, we used the fact that we defined
P(heads)=θ
and that
P(heads)=P(heads∣D,θ)
(this is only the case for coin flipping - not in general).
In general, the posterior predictive distribution is
P(Y∣D,X)=∫θP(Y,θ∣D,X)dθ=∫θP(Y∣θ,D,X)P(θ|D)dθ
Unfortunately, the above is generally intractable in closed form and sampling techniques, such as Monte Carlo approximations, are used to approximate the distribution.
Machine Learning and estimation
In supervised Machine learning you are provided with training data D. You use this data to train a model, represented by its parameters θ. With this model you want to make predictions on a test point xt.
- MLE Prediction: P(y|xt;θ)
Learning: θ=argmaxθP(D;θ). Here θ
Add Answer to:
Alternative
Classification
How to Estimate
Probabilities from Data? ( For continuous Attributes)
And How to generate...
Occupational classification is an example of: A) quantitative data. B) qualitative data. C) continuous data. D)...
Occupational classification is an example of: A) quantitative data. B) qualitative data. C) continuous data. D) dichotomous data.
Discuss how Risk Classification is designed to generate a “mathematically fair” price and how it potentially...
Discuss how Risk Classification is designed to generate a “mathematically fair” price and how it potentially fails to achieve this objective.
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m...
 4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
how to generating the binary code by arithmetic coding 1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the tag and find the corr...
 how to generating the binary code by arithmetic coding
1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the tag and find the corresponding gaps and binary values for each stage and the sequence of the symbols which are coded are ala3a2a4al (25 Marks)
1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the...
how to generating the binary code by arithmetic coding
1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the tag and find the corresponding gaps and binary values for each stage and the sequence of the symbols which are coded are ala3a2a4al (25 Marks)
1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the...
Question 1. Classify the attributes from the following aspects: (1) binary, discrete, or continuous. (2) qualitative...
Question 1. Classify the attributes from the following aspects: (1) binary, discrete, or continuous. (2) qualitative or quantitative. (3) nominal, ordinal, interval, or ratio. Example: Age in years. Answer: Discrete, quantitative, ratio. a. Weight in kg. b. ISBN of a book c. Letter grades: A, B, C, D, F d. Blood type of patient: Type A, Type B, Type O, Type AB, etc.
4. Given a sample of size of moments to estimate the probabilities vector p from a...
 4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
What attributes, columns, or data would allow us to determine churn? Also, how do we categorize...
What attributes, columns, or data would allow us to determine churn? Also, how do we categorize voluntary and involuntary churn with the data?
How does Classification works in Data Mining? Explain 2 paragraph with 2 references. PLEASE
How does Classification works in Data Mining? Explain 2 paragraph with 2 references. PLEASE
Determine whether the given value is from a discrete or continuous data set
Determine whether the given value is from a discrete or continuous data set When a truck is randomly selected, t is found to have a gas tank that can hold 15.9 gal Choose the correct answer below A. It is from a continuous data set because the number of possible values is infinite and not countable B. It is from a discrete data set because the number of passible values is infinite and countable. C. It is from a discrete data set because the number...
- How to Get There From Here sustainable health system has three key attributes. What are...
- How to Get There From Here sustainable health system has three key attributes. What are these three key attributes and what recommendations are offered to ensure efficiency, sustainability, and optimal functioning?
 4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
 how to generating the binary code by arithmetic coding
1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the tag and find the corresponding gaps and binary values for each stage and the sequence of the symbols which are coded are ala3a2a4al (25 Marks)
1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the...
how to generating the binary code by arithmetic coding
1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the tag and find the corresponding gaps and binary values for each stage and the sequence of the symbols which are coded are ala3a2a4al (25 Marks)
1. Assume there are four letters from an information source with probabilities as A1 0.5 A2 0.3 АЗ 0.1 0.1 A4 Generate the...
 4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
4. Given a sample of size of moments to estimate the probabilities vector p from a multinomial (m; pi,.. . ,p,) distribution use the ,Pr) assuming m is method o known - (pi,
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago