We have the following sequence of instructions in assembly language. lw r4, 4($s1) or r1,r2,r3 or...
We have the following sequence of instructions in assembly language.
lw r4, 4($s1)
or r1,r2,r3
or r2,r1,r4
or r1,r1,r2
-
Using your knowledge of piplining and the five stages (IF, ID, EXE, MEM, WB)
-
Assume there is forwarding in this pipelined processor and each stage will take 200ns.
Draw the pipeline chart and calculate how many cycles are consumed
Homework Answers
We are using a traditional 5 stage MIPS pipeline with 5 stages with data forwarding
In forwarding if a result of some instruction is available and is needed somewhere in the future instructions but the result has not been written to the memory, instead of waiting for the result to be written to the memory and stalling the pipeline, we forward the result to the place where is needed.
In the pipeline chart I have used arrows to represent data forwarding.
Given the following sequence of instructions :
I1 : lw r4, 4($s1)
I2 : or r1,r2,r3
I3 : or r2,r1,r4
I4 : or r1,r1,r2
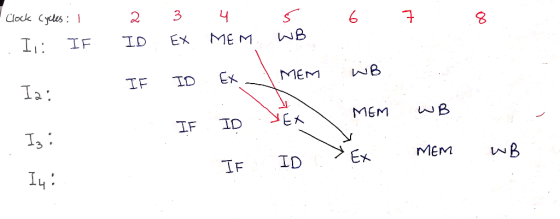
In lw (Load Word) instruction, result is available after the MEM stage and can be forwarded.
In ALU instructions like or instruction, result is available after the EX stage and can be forwarded
The total number of clock cycles consumed is 8
Add Answer to:
We have the following sequence of instructions in assembly
language.
lw r4, 4($s1)
or r1,r2,r3
or...
We have the following sequence of instructions in MIPS lw $t4, 4($s1) or $t1, $t2, $t3...
We have the following sequence of instructions in MIPS lw $t4, 4($s1) or $t1, $t2, $t3 or $t2, $t1, $t4 or $t1, $t1, $t2 1) Indicate any hazards and what the hazard types are. 2) Assume there is no forwarding in this pipelined processor and each stage takes 1 cycle. Draw the pipeline chart and calculate how many cycles are consumed 3) Assume there is forwarding in this pipelined processor and each stage takes 1 cycle. Draw the pipeline chart...
Assembly code time
Consider the following assembly language code:I0: add $R4,$R1,$R0 //ADD R4 = R1 + R0;I1: lw $R1,100($R3) //LDW R1 = MEM[R3 + 100];I2: lw $R9,4,($R1) // LDW R9 = MEM[R1 + 4];I3: add $R3,$R4,$R9 //ADD R3 = R4 + R9;I4: lw $R1,0($R3) //LDW R1 = MEM[R3 + 0];I5: sub $R3,$R1,$R4 //SUB R3 = R1 - R4;I6: and $R9,$R9,$R7 //AND R9 = R9 & R7;I7: sw $R2,100($R4) //STW MEM[R4 + 100] = R2;I8: and $R4,$R2,$R1 //AND R4 = R2 & R1;I9: add...
Ch04.2. [3 points] Consider the following assembly language code: I0: ADD R4 R1RO I1: SUB R9R3 R4...
 Ch04.2. [3 points] Consider the following assembly language code: I0: ADD R4 R1RO I1: SUB R9R3 R4; I2: ADD R4 - R5+R6 I3: LDW R2MEMIR3100]; 14: LDW R2 = MEM [R2 + 0]; 15: STW MEM [R4 + 100] = R3 ; I6: AND R2R2 & R1; 17: BEQ R9R1, Target; I8: AND R9 R9&R1 Consider a pipeline with forwarding, hazard detection, and 1 delay slot for branches. The pipeline is the typical 5-stage IF, ID, EX, MEM, WB MIPS...
Ch04.2. [3 points] Consider the following assembly language code: I0: ADD R4 R1RO I1: SUB R9R3 R4; I2: ADD R4 - R5+R6 I3: LDW R2MEMIR3100]; 14: LDW R2 = MEM [R2 + 0]; 15: STW MEM [R4 + 100] = R3 ; I6: AND R2R2 & R1; 17: BEQ R9R1, Target; I8: AND R9 R9&R1 Consider a pipeline with forwarding, hazard detection, and 1 delay slot for branches. The pipeline is the typical 5-stage IF, ID, EX, MEM, WB MIPS...
Q4. (20 points) Consider the following sequence of instructions being processed on the 5-stage RISC-V pipelined...
 Q4. (20 points) Consider the following sequence of instructions being processed on the 5-stage RISC-V pipelined processor: lw r4, 100 (r2) add r5, r2, r3 sub r6, r4, r5 and r7, r2, r5 I. Identify all the data dependencies in the above instruction sequence. For each dependency, indicate the two instructions and the register that causes the dependency. I Assume that the pipelined uses full forwarding. Draw a pipelined diagram that represents the flow of instructions through the pipeline during...
Q4. (20 points) Consider the following sequence of instructions being processed on the 5-stage RISC-V pipelined processor: lw r4, 100 (r2) add r5, r2, r3 sub r6, r4, r5 and r7, r2, r5 I. Identify all the data dependencies in the above instruction sequence. For each dependency, indicate the two instructions and the register that causes the dependency. I Assume that the pipelined uses full forwarding. Draw a pipelined diagram that represents the flow of instructions through the pipeline during...
(60 points) The following instructions are executed on the 5-stage MIPS pipelined datapath. add r...
 Computer architecture help:
(60 points) The following instructions are executed on the 5-stage MIPS pipelined datapath. add r5,r2, r1 lw r3, 4(r5) lw r2, 0(r2) or r3, r5, r3 sw r3, 0(r5) (a) (20 points) List the data hazards in the above code. For each data hazard identified, clearly mark the source and the destination. For example you can say, there is a data hazard from instruction X to instruction Y on register Z. (b) (20 points) Assume there is...
Computer architecture help:
(60 points) The following instructions are executed on the 5-stage MIPS pipelined datapath. add r5,r2, r1 lw r3, 4(r5) lw r2, 0(r2) or r3, r5, r3 sw r3, 0(r5) (a) (20 points) List the data hazards in the above code. For each data hazard identified, clearly mark the source and the destination. For example you can say, there is a data hazard from instruction X to instruction Y on register Z. (b) (20 points) Assume there is...
4) Consider the following assembly language code: INSTRUCTIONS T01 T02 T03 T04 T05 T06 T07 T08...
4) Consider the following assembly language code: INSTRUCTIONS T01 T02 T03 T04 T05 T06 T07 T08 T09 T10 T11 T12 T13 T14 (as a table) Loop: sll $t1, $s3, 2 add $t1, $t1, $s6 lw $t0, 0($t1) beq $t0, $s5, Exit addi $s3, $s3, 1 j Loop Exit: Use a pipeline with forwarding, hazard detection, and 1 delay slot for branches. The pipeline is the typical 5-stage IF, ID, EX, MEM, WB MIPS design. For the above code, complete the...
Given the following sequence of instructions: lw $s2, 0($s1) //1 lw $s1, 40($s3) //2 sub $s3,...
Given the following sequence of instructions: lw $s2, 0($s1) //1 lw $s1, 40($s3) //2 sub $s3, $s1, $s2 //3 add $s3, $s2, $s2 //4 or $s4, $s3, $zero //5 sw $s3, 50($s1) //6 a. List the read after write (current instruction is reading certain registers which haven’t been written back yet) data dependencies. As an example , 3 on 1 ($s2) shows instruction 3 has data dependency on instruction 1 since it is reading register $s2. b. Assume the 5...
c. The classic five-stage pipeline MIPS architecture is used to execute the code fragments. Assume the...
c. The classic five-stage pipeline MIPS architecture is used to execute the code fragments. Assume the followings: Register write is done in the first half of the clock cycle; register read is performed in the second half of the clock cycle, Branches are resolved in the second stage of the pipeline and the architecture does not utilize any branch prediction mechanism Forwarding is fully supported Clock Cycle à 1 2 3 4 5 6 7 8 9 10 11 12...
2 This exercise is intended to help you understand the relationship between forwarding hazard detection, and...
 2 This exercise is intended to help you understand the relationship between forwarding hazard detection, and ISA design. Problems in this exercise refer to the following sequence of instructions, and assume that it is executed on a 5-stage pipelined datapath: lw r5,4(r5) add r5,r2,r5 Iw r3,0(r5) or r3,r5,r3 sw r4,0(r5) 2.1 If there is no forwarding or hazard detection, how many nops needed to be inserted to ensure correct execution, and how many cycles needed to execute the codes? 2.2...
2 This exercise is intended to help you understand the relationship between forwarding hazard detection, and ISA design. Problems in this exercise refer to the following sequence of instructions, and assume that it is executed on a 5-stage pipelined datapath: lw r5,4(r5) add r5,r2,r5 Iw r3,0(r5) or r3,r5,r3 sw r4,0(r5) 2.1 If there is no forwarding or hazard detection, how many nops needed to be inserted to ensure correct execution, and how many cycles needed to execute the codes? 2.2...
a) Describe the main techniques used by superscalar processors to achieve a high degree of machine-level parallelism. Consider the following assembly code: I1: LOAD r3 (r1) TO 12: MOVE r4 #1 1...
 a) Describe the main techniques used by superscalar processors
to achieve a high degree of machine-level parallelism.
Consider the following assembly code: I1: LOAD r3 (r1) TO 12: MOVE r4 #1 13: ADD r3 r3 r4 I4: LOAD r2 (r2) 15: MOVE r4 #2 I6: MUL r2 r2 r4 17: MUL r3 r3 r2 I8: LOAD r4 (r1) 19: MOVE r1 #3 I10: ADD r4 r4 r1 I11: MUL r3 r3 r4 Using register renaming reorganise the code from the...
a) Describe the main techniques used by superscalar processors
to achieve a high degree of machine-level parallelism.
Consider the following assembly code: I1: LOAD r3 (r1) TO 12: MOVE r4 #1 13: ADD r3 r3 r4 I4: LOAD r2 (r2) 15: MOVE r4 #2 I6: MUL r2 r2 r4 17: MUL r3 r3 r2 I8: LOAD r4 (r1) 19: MOVE r1 #3 I10: ADD r4 r4 r1 I11: MUL r3 r3 r4 Using register renaming reorganise the code from the...
 Ch04.2. [3 points] Consider the following assembly language code: I0: ADD R4 R1RO I1: SUB R9R3 R4; I2: ADD R4 - R5+R6 I3: LDW R2MEMIR3100]; 14: LDW R2 = MEM [R2 + 0]; 15: STW MEM [R4 + 100] = R3 ; I6: AND R2R2 & R1; 17: BEQ R9R1, Target; I8: AND R9 R9&R1 Consider a pipeline with forwarding, hazard detection, and 1 delay slot for branches. The pipeline is the typical 5-stage IF, ID, EX, MEM, WB MIPS...
Ch04.2. [3 points] Consider the following assembly language code: I0: ADD R4 R1RO I1: SUB R9R3 R4; I2: ADD R4 - R5+R6 I3: LDW R2MEMIR3100]; 14: LDW R2 = MEM [R2 + 0]; 15: STW MEM [R4 + 100] = R3 ; I6: AND R2R2 & R1; 17: BEQ R9R1, Target; I8: AND R9 R9&R1 Consider a pipeline with forwarding, hazard detection, and 1 delay slot for branches. The pipeline is the typical 5-stage IF, ID, EX, MEM, WB MIPS...
 Q4. (20 points) Consider the following sequence of instructions being processed on the 5-stage RISC-V pipelined processor: lw r4, 100 (r2) add r5, r2, r3 sub r6, r4, r5 and r7, r2, r5 I. Identify all the data dependencies in the above instruction sequence. For each dependency, indicate the two instructions and the register that causes the dependency. I Assume that the pipelined uses full forwarding. Draw a pipelined diagram that represents the flow of instructions through the pipeline during...
Q4. (20 points) Consider the following sequence of instructions being processed on the 5-stage RISC-V pipelined processor: lw r4, 100 (r2) add r5, r2, r3 sub r6, r4, r5 and r7, r2, r5 I. Identify all the data dependencies in the above instruction sequence. For each dependency, indicate the two instructions and the register that causes the dependency. I Assume that the pipelined uses full forwarding. Draw a pipelined diagram that represents the flow of instructions through the pipeline during...
 Computer architecture help:
(60 points) The following instructions are executed on the 5-stage MIPS pipelined datapath. add r5,r2, r1 lw r3, 4(r5) lw r2, 0(r2) or r3, r5, r3 sw r3, 0(r5) (a) (20 points) List the data hazards in the above code. For each data hazard identified, clearly mark the source and the destination. For example you can say, there is a data hazard from instruction X to instruction Y on register Z. (b) (20 points) Assume there is...
Computer architecture help:
(60 points) The following instructions are executed on the 5-stage MIPS pipelined datapath. add r5,r2, r1 lw r3, 4(r5) lw r2, 0(r2) or r3, r5, r3 sw r3, 0(r5) (a) (20 points) List the data hazards in the above code. For each data hazard identified, clearly mark the source and the destination. For example you can say, there is a data hazard from instruction X to instruction Y on register Z. (b) (20 points) Assume there is...
 2 This exercise is intended to help you understand the relationship between forwarding hazard detection, and ISA design. Problems in this exercise refer to the following sequence of instructions, and assume that it is executed on a 5-stage pipelined datapath: lw r5,4(r5) add r5,r2,r5 Iw r3,0(r5) or r3,r5,r3 sw r4,0(r5) 2.1 If there is no forwarding or hazard detection, how many nops needed to be inserted to ensure correct execution, and how many cycles needed to execute the codes? 2.2...
2 This exercise is intended to help you understand the relationship between forwarding hazard detection, and ISA design. Problems in this exercise refer to the following sequence of instructions, and assume that it is executed on a 5-stage pipelined datapath: lw r5,4(r5) add r5,r2,r5 Iw r3,0(r5) or r3,r5,r3 sw r4,0(r5) 2.1 If there is no forwarding or hazard detection, how many nops needed to be inserted to ensure correct execution, and how many cycles needed to execute the codes? 2.2...
 a) Describe the main techniques used by superscalar processors
to achieve a high degree of machine-level parallelism.
Consider the following assembly code: I1: LOAD r3 (r1) TO 12: MOVE r4 #1 13: ADD r3 r3 r4 I4: LOAD r2 (r2) 15: MOVE r4 #2 I6: MUL r2 r2 r4 17: MUL r3 r3 r2 I8: LOAD r4 (r1) 19: MOVE r1 #3 I10: ADD r4 r4 r1 I11: MUL r3 r3 r4 Using register renaming reorganise the code from the...
a) Describe the main techniques used by superscalar processors
to achieve a high degree of machine-level parallelism.
Consider the following assembly code: I1: LOAD r3 (r1) TO 12: MOVE r4 #1 13: ADD r3 r3 r4 I4: LOAD r2 (r2) 15: MOVE r4 #2 I6: MUL r2 r2 r4 17: MUL r3 r3 r2 I8: LOAD r4 (r1) 19: MOVE r1 #3 I10: ADD r4 r4 r1 I11: MUL r3 r3 r4 Using register renaming reorganise the code from the...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago