In object recognition, translating an image by a few pixels in some direction should not affect...
In object recognition, translating an image by a few pixels in some direction should not affect the category recognized. Suppose that we consider images with an object in the foreground on top of a uniform background. Suppose also that the objects of interest are always at least 10 pixels away from the borders of the image. Are the following neural networks invariant to translations of at most 10 pixels in some direction?
Here the translation is applied only to the foreground object while keeping the background fixed. If your answer is yes, show that the neural network will necessarily produce the same output for two images where the foreground object is translated by at most 10 pixels. If your answer is no, provide a counter example by describing a situation where the output of the neural network is different for two images where the foreground object is translated by at most 10 pixels.
(a) Neural network with one hidden layer consisting of convolutions (5x5 patches with a stride of 1 in each direction) and a softmax output layer.
(b) Neural network with two hidden layers consisting of convolutions (5x5 patches with a stride of 1 in each direction) followed by max pooling (4x4 patches with a stride of 4 in each direction) and a softmax output layer.
Homework Answers
Welcome to Chegg!
The neural network will be able to detect the object as it is. If we normalize the image then it makes no difference to the overall image, since the overall image (area of interest) remains the same.
Extract features of the image (object or object characteristics) which remains same with respect to translation of the image and create a classifier based on these features.
The normalization can be done if we consider geometric moments as follows:

Total mass and position of the center of mass can be found by
 respectively.
respectively.
So, to make translation invariant image, change the image
 to
to 
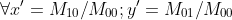
These equations are true for a single hidden layer as well as a multi hidden layer. So, apply these equations two times from in part 'b' above.
Softmax output can be found by applying the following equation (once in both the parts):

Images for part 'a' and 'b' are given below for representation
purpose (Downloaded from the internet).

Thanks for using Chegg! :)
Add Answer to:
In object recognition, translating an image by a few pixels in
some direction should not affect...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago