In this task, we will investigate the difference between hash function’s two perperties: one-way property versus...
In this task, we will investigate the difference between hash function’s two perperties: one-way property versus collision-free property. We will use the brute-force method to see how long it takes to break each of these properties. Instead of using openssl’s command-line tools, you are required to write our own C programs to invoke the message digest functions in openssl’s crypto library. A sample code can be found from http://www.openssl.org/docs/crypto/EVP_DigestInit.html. Please get familiar with this sample code. Since most of the hash functions are quite strong against the brute-force attack on those two properties, it will take us years to break them using the brute-force method. To make the task feasible, we reduce the length of the hash value to 24 bits. We can use any one-way hash function, but we only use the first 24 bits of the hash value in this task. Namely, we are using a modified one-way hash function. Please design an experiment to find out the following:
1. How many trials it will take you to break the one-way property using the brute-force method? You should repeat your experiment for multiple times, and report your average number of trials.
2. How many trials it will take you to break the collision-free property using the brute-force method? Similarly, you should report the average.
3. Based on your observation, which property is easier to break using the brute-force method?
Homework Answers
BACKGROUND:
HASH COLLISION FREE PROPERTY (COLLISION FREE HASH FUNCTION) :
One-way function :
In computer science, a one-way function is a function that is easy to compute on every input, but hard to invert given the image of a random input. Here, "easy" and "hard" are to be understood in the sense of computational complexity theory, specifically the theory of polynomial time problems. Not being one-to-one is not considered sufficient of a function for it to be called one-way (see Theoretical Definition, below).
The existence of such one-way functions is still an open conjecture. In fact, their existence would prove that the complexity classes P and NP are not equal, thus resolving the foremost unsolved question of theoretical computer science. The converse is not known to be true, i.e. the existence of a proof that P and NP are not equal would not directly imply the existence of one-way functions.
In applied contexts, the terms "easy" and "hard" are usually interpreted relative to some specific computing entity; typically "cheap enough for the legitimate users" and "prohibitively expensive for any malicious agents". One-way functions, in this sense, are fundamental tools for cryptography, personal identification, authentication, and other data security applications. While the existence of one-way functions in this sense is also an open conjecture, there are several candidates that have withstood decades of intense scrutiny. Some of them are essential ingredients of most telecommunications, e-commerce, and e-banking systems around the world.
Theoretical definition
A function f : {0,1}* → {0,1}* is
one-way if and only if f can be computed
by a polynomial time algorithm, but any polynomial time randomized
algorithm  that attempts to compute a pseudo-inverse for f succeeds
with negligible probability. That is, for all randomized algorithms
, all positive integers c and all sufficiently large
n = length(x) ,
that attempts to compute a pseudo-inverse for f succeeds
with negligible probability. That is, for all randomized algorithms
, all positive integers c and all sufficiently large
n = length(x) ,
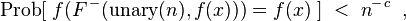
where unary(n) is the string of n 1s and the
probability is over the choice of x from the discrete
uniform distribution on {0,1}n, and the
randomness of
.[3]
Note that, by this definition, the function must be "hard to invert" in the average-case, rather than worst-case sense. This is different from much of complexity theory (e.g., NP-hardness), where the term "hard" is meant in the worst-case. That's why even if some candidates for one-way functions (described below) are known to be NP-complete, it does not imply their one-ways. The latter property is only based on the lack of known algorithm to solve the problem.
It is not sufficient to make a function "lossy" (not one-to-one) to have a one-way function. In particular, the function that outputs the string of n zeros on any input of length n is not a one-way function because it is easy to come up with an input that will result in the same output. More precisely: For a function that simply outputs a string of zeroes, an algorithm F− that just outputs any string of length n on input f(x) will "find" a proper preimage of the output, even if it is not the input which was originally used to find the output string.
Theoretical implications of one-way functions
If f is a one-way function, then the inversion of f would be a problem whose output is hard to compute (by definition) but easy to check (just by computing f on it). Thus, the existence of a one-way function implies that FP≠FNP, which in turn implies that P≠NP. However, it is not known whether P≠NP implies the existence of one-way functions.
The existence of a one-way function implies the existence of many other useful concepts, including:
- Pseudorandom generators
- Pseudorandom function families
- Bit commitment schemes
- Private-key encryption schemes secure against adaptive chosen-ciphertext attack
- Message authentication codes
- Digital signature schemes (secure against adaptive chosen-message attack)
The existence of one-way functions also implies that there is no natural proof for P≠NP.
Candidates for one-way functions
The following are several candidates for one-way functions.Clearly, it is not known whether these functions are indeed one-way; but extensive research has so far failed to produce an efficient inverting algorithm for any of them.
Multiplication and factoring
The function f takes as inputs two prime numbers
p and q in binary notation and returns their
product. This function can be "easily" computed in
O(n2) time, where n is the
total length (number of bits) of the inputs. Inverting this
function requires finding the factors of a given integer
N. The best factoring algorithms known run in  time, which is only pseudo-polynomial in
time, which is only pseudo-polynomial in  , the number of bits needed to represent N.
, the number of bits needed to represent N.
This function can be generalized by allowing p and q to range over a suitable set of semiprimes. Note that f is not one-way for arbitrary p,q>1, since the product will have 2 as a factor with probability 3/4 (because the probability that an arbitrary p is odd is 1/2, and likewise for q, so if they're chosen independently, the probability that both are odd is therefore 1/4; hence the probability that neither is odd is 1 - 1/4 = 3/4).
The Rabin function (modular squaring)[edit]
The Rabin function,or squaring modulo  , where
, where  and
and  are primes is believed to be a collection of one-way functions. We
write
are primes is believed to be a collection of one-way functions. We
write

to denote squaring modulo  : a specific member of the Rabin collection. It
can be shown that extracting square roots, i.e. inverting the Rabin
function, is computationally equivalent to factoring
(in the sense of polynomial-time reduction). Hence it can be
proven that the Rabin collection is one-way if and only if
factoring is hard. This also holds for the special case in which
and
are of the same bit length. The Rabin cryptosystem is based on the
assumption that this Rabin function is one-way.
: a specific member of the Rabin collection. It
can be shown that extracting square roots, i.e. inverting the Rabin
function, is computationally equivalent to factoring
(in the sense of polynomial-time reduction). Hence it can be
proven that the Rabin collection is one-way if and only if
factoring is hard. This also holds for the special case in which
and
are of the same bit length. The Rabin cryptosystem is based on the
assumption that this Rabin function is one-way.
Discrete exponential and logarithm
The function f takes a prime number p and an integer x between 0 and p−1; and returns the remainder of 2x divided by p. Modular exponentiation can be done in time O(n3) where n is the number of bits in p. Inverting this function requires computing the discrete logarithm modulo p; namely, given a prime p and an integer y between 0 and p−1, find x, such that 2x = y. As of 2009, there is no published algorithm for this problem that runs in polynomial time. The ElGamal encryption scheme is based on this function.
Cryptographically secure hash functions
There are a number of cryptographic hash functions that are fast to compute like SHA 256. Some of the simpler versions have fallen to sophisticated analysis, but the strongest versions continue to offer fast, practical solutions for one-way computation. Most of the theoretical support for the functions are more techniques for thwarting some of the previously successful attacks.
Elliptic curves
An elliptic curve is a set of pairs of elements of a field satisfying y2 = x3 + ax + b. For cryptography, finite fields must be used. The elements of the curve form a group under an operation called "point addition" (which is not the same as the addition operation of the field). Multiplication kP of a point P by an integer k is defined as repeated addition of the point to itself. If k and P are known, it is easy to compute R=kP, but if only R and P are known, it is assumed to be hard to compute k.
Other candidates
Other candidates for one-way functions have been based on the hardness of the decoding of random linear codes, the subset sum problem (Naccache-Stern knapsack cryptosystem), or other problems.
Universal one-way function
There is an explicit function f that has been proved to be one-way, if and only if one-way functions exist.In other words, if any function is one-way, then so is f. Since this function was the first combinatorial complete one-way function to be demonstrated, it is known as the "universal one-way function". The problem of determining the existence of one-way functions is thus reduced to the problem of proving that this specific function is one-way.
INTRODUCTION ALONG WITH AN EXAMPLE:
The EVP interface to message digests should almost always be used in preference to the low level interfaces. This is because the code then becomes transparent to the digest used and much more flexible.
New applications should use SHA2 digest algorithms such as SHA256. The other digest algorithms are still in common use.
For most applications, the impl parameter to EVP_DigestInit_ex() will be set to NULL to use the default digest implementation.
The functions EVP_DigestInit(), EVP_DigestFinal() and EVP_MD_CTX_copy() are obsolete but are retained to maintain compatibility with existing code. New applications should use EVP_DigestInit_ex(), EVP_DigestFinal_ex() and EVP_MD_CTX_copy_ex() because they can efficiently reuse a digest context instead of initializing and cleaning it up on each call and allow non default implementations of digests to be specified.
If digest contexts are not cleaned up after use memory leaks will occur.
EVP_MD_CTX_size(), EVP_MD_CTX_block_size(), EVP_MD_CTX_type(), EVP_get_digestbynid() and EVP_get_digestbyobj() are defined as macros.
EXAMPLE
This example digests the data "Test Message\n" and "Hello World\n", using the digest name passed on the command line.
#include <stdio.h>
#include <openssl/evp.h>
main(int argc, char *argv[])
{
EVP_MD_CTX *mdctx;
const EVP_MD *md;
char mess1[] = "Test Message\n";
char mess2[] = "Hello World\n";
unsigned char md_value[EVP_MAX_MD_SIZE];
int md_len, i;
if(!argv[1]) {
printf("Usage: mdtest digestname\n");
exit(1);
}
md = EVP_get_digestbyname(argv[1]);
if(!md) {
printf("Unknown message digest %s\n", argv[1]);
exit(1);
}
mdctx = EVP_MD_CTX_new();
EVP_DigestInit_ex(mdctx, md, NULL);
EVP_DigestUpdate(mdctx, mess1, strlen(mess1));
EVP_DigestUpdate(mdctx, mess2, strlen(mess2));
EVP_DigestFinal_ex(mdctx, md_value, &md_len);
EVP_MD_CTX_free(mdctx);
printf("Digest is: ");
for(i = 0; i < md_len; i++)
printf("%02x", md_value[i]);
printf("\n");
/* Call this once before exit. */
EVP_cleanup();
exit(0);
}
SEE ALSO
dgst, evp
HISTORY
EVP_MD_CTX became opaque in OpenSSL 1.1. Consequently, stack allocated EVP_MD_CTXs are no longer supported.
EVP_MD_CTX_create() and EVP_MD_CTX_destroy() were renamed to EVP_MD_CTX_new() and EVP_MD_CTX_free() in OpenSSL 1.1.
The link between digests and signing algorithms was fixed in OpenSSL 1.0 and later, so now EVP_sha1() can be used with RSA and DSA. The legacy EVP_dss1() was removed in OpenSSL 1.1.0
EVP_DigestInit
NAME
EVP_MD_CTX_new, EVP_MD_CTX_reset, EVP_MD_CTX_free, EVP_MD_CTX_copy_ex, EVP_DigestInit_ex, EVP_DigestUpdate, EVP_DigestFinal_ex, EVP_MAX_MD_SIZE, EVP_DigestInit, EVP_DigestFinal, EVP_MD_CTX_copy, EVP_MD_type, EVP_MD_pkey_type, EVP_MD_size, EVP_MD_block_size, EVP_MD_CTX_md, EVP_MD_CTX_size, EVP_MD_CTX_block_size, EVP_MD_CTX_type, EVP_md_null, EVP_md2, EVP_md5, EVP_sha1, EVP_sha224, EVP_sha256, EVP_sha384, EVP_sha512, EVP_mdc2, EVP_ripemd160, EVP_blake2b_512, EVP_blake2s_256, EVP_get_digestbyname, EVP_get_digestbynid, EVP_get_digestbyobj - EVP digest routines
SYNOPSIS
#include <openssl/evp.h>
EVP_MD_CTX *EVP_MD_CTX_new(void);
int EVP_MD_CTX_reset(EVP_MD_CTX *ctx);
void EVP_MD_CTX_free(EVP_MD_CTX *ctx);
int EVP_DigestInit_ex(EVP_MD_CTX *ctx, const EVP_MD *type, ENGINE *impl);
int EVP_DigestUpdate(EVP_MD_CTX *ctx, const void *d, size_t cnt);
int EVP_DigestFinal_ex(EVP_MD_CTX *ctx, unsigned char *md,
unsigned int *s);
int EVP_MD_CTX_copy_ex(EVP_MD_CTX *out,const EVP_MD_CTX *in);
int EVP_DigestInit(EVP_MD_CTX *ctx, const EVP_MD *type);
int EVP_DigestFinal(EVP_MD_CTX *ctx, unsigned char *md,
unsigned int *s);
int EVP_MD_CTX_copy(EVP_MD_CTX *out,EVP_MD_CTX *in);
#define EVP_MAX_MD_SIZE 64 /* SHA512 */
int EVP_MD_type(const EVP_MD *md);
int EVP_MD_pkey_type(const EVP_MD *md);
int EVP_MD_size(const EVP_MD *md);
int EVP_MD_block_size(const EVP_MD *md);
const EVP_MD *EVP_MD_CTX_md(const EVP_MD_CTX *ctx);
int (*EVP_MD_CTX_update_fn(EVP_MD_CTX *ctx))(EVP_MD_CTX *ctx,
const void *data, size_t count);
void EVP_MD_CTX_set_update_fn(EVP_MD_CTX *ctx,
int (*update) (EVP_MD_CTX *ctx,
const void *data, size_t count));
int EVP_MD_CTX_size(const EVP_MD *ctx);
int EVP_MD_CTX_block_size(const EVP_MD *ctx);
int EVP_MD_CTX_type(const EVP_MD *ctx);
EVP_PKEY_CTX *EVP_MD_CTX_pkey_ctx(const EVP_MD_CTX *ctx);
void *EVP_MD_CTX_md_data(const EVP_MD_CTX *ctx);
const EVP_MD *EVP_md_null(void);
const EVP_MD *EVP_md2(void);
const EVP_MD *EVP_md5(void);
const EVP_MD *EVP_sha1(void);
const EVP_MD *EVP_mdc2(void);
const EVP_MD *EVP_ripemd160(void);
const EVP_MD *EVP_blake2b_512(void);
const EVP_MD *EVP_blake2s_256(void);
const EVP_MD *EVP_sha224(void);
const EVP_MD *EVP_sha256(void);
const EVP_MD *EVP_sha384(void);
const EVP_MD *EVP_sha512(void);
const EVP_MD *EVP_get_digestbyname(const char *name);
const EVP_MD *EVP_get_digestbynid(int type);
const EVP_MD *EVP_get_digestbyobj(const ASN1_OBJECT *o);
DESCRIPTION
The EVP digest routines are a high level interface to message digests, and should be used instead of the cipher-specific functions.
EVP_MD_CTX_new() allocates, initializes and returns a digest context.
EVP_MD_CTX_reset() resets the digest context ctx. This can be used to reuse an already existing context.
EVP_MD_CTX_free() cleans up digest context ctx and frees up the space allocated to it.
EVP_DigestInit_ex() sets up digest context ctx to use a digest type from ENGINE impl. ctx must be initialized before calling this function. type will typically be supplied by a function such as EVP_sha1(). If impl is NULL then the default implementation of digest type is used.
EVP_DigestUpdate() hashes cnt bytes of data at d into the digest context ctx. This function can be called several times on the same ctx to hash additional data.
EVP_DigestFinal_ex() retrieves the digest value from ctx and places it in md. If the s parameter is not NULL then the number of bytes of data written (i.e. the length of the digest) will be written to the integer at s, at most EVP_MAX_MD_SIZE bytes will be written. After calling EVP_DigestFinal_ex() no additional calls to EVP_DigestUpdate() can be made, but EVP_DigestInit_ex() can be called to initialize a new digest operation.
EVP_MD_CTX_copy_ex() can be used to copy the message digest state from in to out. This is useful if large amounts of data are to be hashed which only differ in the last few bytes. out must be initialized before calling this function.
EVP_DigestInit() behaves in the same way as EVP_DigestInit_ex() except the passed context ctx does not have to be initialized, and it always uses the default digest implementation.
EVP_DigestFinal() is similar to EVP_DigestFinal_ex() except the digest context ctx is automatically cleaned up.
EVP_MD_CTX_copy() is similar to EVP_MD_CTX_copy_ex() except the destination out does not have to be initialized.
EVP_MD_size() and EVP_MD_CTX_size() return the size of the message digest when passed anEVP_MD or an EVP_MD_CTX structure, i.e. the size of the hash.
EVP_MD_block_size() and EVP_MD_CTX_block_size() return the block size of the message digest when passed an EVP_MD or an EVP_MD_CTX structure.
EVP_MD_type() and EVP_MD_CTX_type() return the NID of the OBJECT IDENTIFIER representing the given message digest when passed an EVP_MD structure. For example EVP_MD_type(EVP_sha1()) returns NID_sha1. This function is normally used when setting ASN1 OIDs.
EVP_MD_CTX_md() returns the EVP_MD structure corresponding to the passed EVP_MD_CTX.
EVP_MD_pkey_type() returns the NID of the public key signing algorithm associated with this digest. For example EVP_sha1() is associated with RSA so this will returnNID_sha1WithRSAEncryption. Since digests and signature algorithms are no longer linked this function is only retained for compatibility reasons.
EVP_md2(), EVP_md5(), EVP_sha1(), EVP_sha224(), EVP_sha256(), EVP_sha384(), EVP_sha512(), EVP_mdc2(), EVP_ripemd160(), EVP_blake2b_512(), and EVP_blake2s_256() return EVP_MDstructures for the MD2, MD5, SHA1, SHA224, SHA256, SHA384, SHA512, MDC2, RIPEMD160, BLAKE2b-512, and BLAKE2s-256 digest algorithms respectively.
EVP_md_null() is a "null" message digest that does nothing: i.e. the hash it returns is of zero length.
EVP_get_digestbyname(), EVP_get_digestbynid() and EVP_get_digestbyobj() return an EVP_MDstructure when passed a digest name, a digest NID or an ASN1_OBJECT structure respectively.
RETURN VALUES
EVP_DigestInit_ex(), EVP_DigestUpdate() and EVP_DigestFinal_ex() return 1 for success and 0 for failure.
EVP_MD_CTX_copy_ex() returns 1 if successful or 0 for failure.
EVP_MD_type(), EVP_MD_pkey_type() and EVP_MD_type() return the NID of the corresponding OBJECT IDENTIFIER or NID_undef if none exists.
EVP_MD_size(), EVP_MD_block_size(), EVP_MD_CTX_size() and EVP_MD_CTX_block_size() return the digest or block size in bytes.
EVP_md_null(), EVP_md2(), EVP_md5(), EVP_sha1(), EVP_mdc2(), EVP_ripemd160(), EVP_blake2b_512(), and EVP_blake2s_256() return pointers to the corresponding EVP_MD structures.
EVP_get_digestbyname(), EVP_get_digestbynid() and EVP_get_digestbyobj() return either anEVP_MD structure or NULL if an error occurs.
Add Answer to:
In this task, we will investigate the difference between hash
function’s two perperties: one-way property versus...
3 Brute Force Attack vs Birthday Attack (50 pts) Message-Digest Algorithm (MD5) and Secure Hash Algorithm 1 (SHA...
 3 Brute Force Attack vs Birthday Attack (50 pts) Message-Digest Algorithm (MD5) and Secure Hash Algorithm 1 (SHA-1) are com- monly used cryptographic hash functions 1. Do research to find the numbers of bits used in MD5 and SHA-1. (8 pts) perform An adversary an attack to a hash algorithm by applying random inputs can and y (y) that satisfie Hx) and repeating until finding two inputs H(y) where H() denotes a hash code. This is called a "hash collision."...
3 Brute Force Attack vs Birthday Attack (50 pts) Message-Digest Algorithm (MD5) and Secure Hash Algorithm 1 (SHA-1) are com- monly used cryptographic hash functions 1. Do research to find the numbers of bits used in MD5 and SHA-1. (8 pts) perform An adversary an attack to a hash algorithm by applying random inputs can and y (y) that satisfie Hx) and repeating until finding two inputs H(y) where H() denotes a hash code. This is called a "hash collision."...
Chapter 06 Applied Cryptography 1. How is integrity provided? A. Using two-way hash functions and digital...
Chapter 06 Applied Cryptography 1. How is integrity provided? A. Using two-way hash functions and digital signatures B. Using one-way hash functions and digital signatures C. By applying a digital certificate D. By using asymmetric encryption 2. Which term refers to the matching of a user to an account through previously shared credentials? A. Nonrepudiation B. Digital signing C. Authentication D. Obfuscation 3. Which term refers to an arranged group of algorithms? A. Crypto modules B. Cryptographic service providers (CSPs)...
Task Algorithms: Pattern Matching (in java) Write a program that gets two strings from user, size...
Task Algorithms: Pattern Matching (in java) Write a program that gets two strings from user, size and pattern, and checks if pattern exists inside size, if it exists then program returns index of first character of pattern inside size, otherwise it returns -1. The method should not use built-in methods such as indexOf , find, etc. Only charAt and length are allowed to use. Analyze the time complexity of your algorithm. Your solution is not allowed to be> = O...
please use Java!! We are storing the inventory for our fruit stand in a hash table....
 please use Java!!
We are storing the inventory for our fruit stand in a hash table. The attached file shows all the possible key/fruit combinations that can be inserted into your hash table. These are the real price lookup values for the corresponding fruit. Problem Description In this programming assignment, you will implement a hash table class fruitHash. Your hash table must include the following methods: 1) hashFunction(key) This method takes a key as an argument and returns the address...
please use Java!!
We are storing the inventory for our fruit stand in a hash table. The attached file shows all the possible key/fruit combinations that can be inserted into your hash table. These are the real price lookup values for the corresponding fruit. Problem Description In this programming assignment, you will implement a hash table class fruitHash. Your hash table must include the following methods: 1) hashFunction(key) This method takes a key as an argument and returns the address...
Hash Tables. (Hint: Diagrams might be helpful for parts a) and b). ) When inserting into...
Hash Tables. (Hint: Diagrams might be helpful for parts a) and b). ) When inserting into hash table we insert at an index calculated by the key modulo the array size, what would happen if we instead did key mod (array_size*2), or key mod (array_size/2)? (Describe both cases). Theory answer Here Change your hashtable from the labs/assignments to be an array of linkedlists – so now insertion is done into a linkedlist at that index. Implement insertion and search. This...
Computer Science C++ Help, here's the question that needs to be answered (TASK D): Task D....
Computer Science C++ Help, here's the question that needs to be answered (TASK D): Task D. Decryption Implement two decryption functions corresponding to the above ciphers. When decrypting ciphertext, ensure that the produced decrypted string is equal to the original plaintext: decryptCaesar(ciphertext, rshift) == plaintext decryptVigenere(ciphertext, keyword) == plaintext Write a program decryption.cpp that uses the above functions to demonstrate encryption and decryption for both ciphers. It should first ask the user to input plaintext, then ask for a right...
help me with this. Im done with task 1 and on the way to do task...
 help me with this. Im done with task 1 and on the way to do task
2. but I don't know how to do it. I attach 2 file function of rksys
and ode45 ( the first is rksys and second is ode 45) . thank for
your help
Consider the spring-mass damper that can be used to model many dynamic systems -- ----- ------- m Applying Newton's Second Law to a free-body diagram of the mass m yields the...
help me with this. Im done with task 1 and on the way to do task
2. but I don't know how to do it. I attach 2 file function of rksys
and ode45 ( the first is rksys and second is ode 45) . thank for
your help
Consider the spring-mass damper that can be used to model many dynamic systems -- ----- ------- m Applying Newton's Second Law to a free-body diagram of the mass m yields the...
Problem 8 In class, we discussed the difference between a pure (or effect-free) function (i.e. one...
 Problem 8 In class, we discussed the difference between a pure (or effect-free) function (i.e. one that returns a value, but does not produce an effect) and a mutating function i.e one that changes the value of its parameters). In this exercise, we ask you to demonstrate your understanding o this distinction by implementing the same functionality as both a pure function, and as a mutating function. Both functions take a list of int as a parameter. The pure variant...
Problem 8 In class, we discussed the difference between a pure (or effect-free) function (i.e. one that returns a value, but does not produce an effect) and a mutating function i.e one that changes the value of its parameters). In this exercise, we ask you to demonstrate your understanding o this distinction by implementing the same functionality as both a pure function, and as a mutating function. Both functions take a list of int as a parameter. The pure variant...
i need this in C# please can any one help me out and write the full...
i need this in C# please can any one help me out and write the full code start from using system till end i am confused and C# is getting me hard.I saw codes from old posts in Chegg but i need the ful complete code please thanks. Module 4 Programming Assignment – OO Design and implementation (50 points) Our Battleship game needs to store a set of ships. Create a new class called Ships. Ships should have the following...
We have a lab report contains two experiments about standing waves. The first one is using...
We have a lab report contains two experiments about standing waves. The first one is using a machine which can provide fixed frequency 60Hz and one string which one said is tied with this machine and another side is attached with mass. After changing the mass every time, we can get different waves with a different mode. The second one is using a metal spring on the floor, Have two members of your group hold the two ends of spring,...
 3 Brute Force Attack vs Birthday Attack (50 pts) Message-Digest Algorithm (MD5) and Secure Hash Algorithm 1 (SHA-1) are com- monly used cryptographic hash functions 1. Do research to find the numbers of bits used in MD5 and SHA-1. (8 pts) perform An adversary an attack to a hash algorithm by applying random inputs can and y (y) that satisfie Hx) and repeating until finding two inputs H(y) where H() denotes a hash code. This is called a "hash collision."...
3 Brute Force Attack vs Birthday Attack (50 pts) Message-Digest Algorithm (MD5) and Secure Hash Algorithm 1 (SHA-1) are com- monly used cryptographic hash functions 1. Do research to find the numbers of bits used in MD5 and SHA-1. (8 pts) perform An adversary an attack to a hash algorithm by applying random inputs can and y (y) that satisfie Hx) and repeating until finding two inputs H(y) where H() denotes a hash code. This is called a "hash collision."...
 please use Java!!
We are storing the inventory for our fruit stand in a hash table. The attached file shows all the possible key/fruit combinations that can be inserted into your hash table. These are the real price lookup values for the corresponding fruit. Problem Description In this programming assignment, you will implement a hash table class fruitHash. Your hash table must include the following methods: 1) hashFunction(key) This method takes a key as an argument and returns the address...
please use Java!!
We are storing the inventory for our fruit stand in a hash table. The attached file shows all the possible key/fruit combinations that can be inserted into your hash table. These are the real price lookup values for the corresponding fruit. Problem Description In this programming assignment, you will implement a hash table class fruitHash. Your hash table must include the following methods: 1) hashFunction(key) This method takes a key as an argument and returns the address...
 help me with this. Im done with task 1 and on the way to do task
2. but I don't know how to do it. I attach 2 file function of rksys
and ode45 ( the first is rksys and second is ode 45) . thank for
your help
Consider the spring-mass damper that can be used to model many dynamic systems -- ----- ------- m Applying Newton's Second Law to a free-body diagram of the mass m yields the...
help me with this. Im done with task 1 and on the way to do task
2. but I don't know how to do it. I attach 2 file function of rksys
and ode45 ( the first is rksys and second is ode 45) . thank for
your help
Consider the spring-mass damper that can be used to model many dynamic systems -- ----- ------- m Applying Newton's Second Law to a free-body diagram of the mass m yields the...
 Problem 8 In class, we discussed the difference between a pure (or effect-free) function (i.e. one that returns a value, but does not produce an effect) and a mutating function i.e one that changes the value of its parameters). In this exercise, we ask you to demonstrate your understanding o this distinction by implementing the same functionality as both a pure function, and as a mutating function. Both functions take a list of int as a parameter. The pure variant...
Problem 8 In class, we discussed the difference between a pure (or effect-free) function (i.e. one that returns a value, but does not produce an effect) and a mutating function i.e one that changes the value of its parameters). In this exercise, we ask you to demonstrate your understanding o this distinction by implementing the same functionality as both a pure function, and as a mutating function. Both functions take a list of int as a parameter. The pure variant...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 11 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 11 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 11 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 11 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 11 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 11 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 11 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 11 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 11 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 11 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 11 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 11 months ago