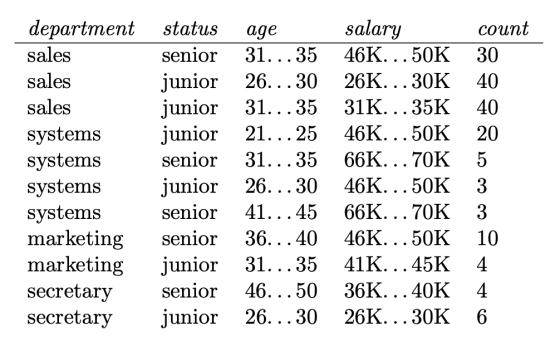
Given a data tuple having the values “systems,” “26...30,” and “46–50K” for the attributes department, age, and salarry, respectively, what would naiive Bayesian classification of the status for the tuple be?
The answer is "P(X|senior) = 0; P(X|junior) = 0.018. Thus, a naiive Bayesian classification predicts “junior”." Or I am not sure about that answer.
PLEASE explain the SOLUTION IN DETAIL.
Thank you!
Homework Answers

Add Answer to:
Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age,...
Given a data tuple having the values “systems,” “26...30,” and “46–50K” for the attributes department, age,...
 Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age, and salarry,
respectively, what would naiive Bayesian classification of the
status for the tuple be? The answer is "P(X|senior) = 0;
P(X|junior) = 0.018. Thus, a naiive Bayesian classification
predicts “junior”." Or I am not sure about that answer. PLEASE
explain the SOLUTION IN DETAIL. Thank you!
department salary status соиnt age 31... 35 sales 46K. ..50K 30 senior 26K. .. 30K 31K... 35K...
Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age, and salarry,
respectively, what would naiive Bayesian classification of the
status for the tuple be? The answer is "P(X|senior) = 0;
P(X|junior) = 0.018. Thus, a naiive Bayesian classification
predicts “junior”." Or I am not sure about that answer. PLEASE
explain the SOLUTION IN DETAIL. Thank you!
department salary status соиnt age 31... 35 sales 46K. ..50K 30 senior 26K. .. 30K 31K... 35K...
The following table consists of training data from an employee database. The data have been generalized....
 The following table consists of training data from an employee
database. The data
have been generalized. For example, “31 . . . 35” for age
represents the age range
of 31 to 35. For a given row entry, count represents the
number of data tuples
having the values for department, status, age, and salary
given in that row.
department status age salary count
sales senior 31. . . 35 46K. . . 50K 30
sales junior 26. . . 30...
The following table consists of training data from an employee
database. The data
have been generalized. For example, “31 . . . 35” for age
represents the age range
of 31 to 35. For a given row entry, count represents the
number of data tuples
having the values for department, status, age, and salary
given in that row.
department status age salary count
sales senior 31. . . 35 46K. . . 50K 30
sales junior 26. . . 30...
 Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age, and salarry,
respectively, what would naiive Bayesian classification of the
status for the tuple be? The answer is "P(X|senior) = 0;
P(X|junior) = 0.018. Thus, a naiive Bayesian classification
predicts “junior”." Or I am not sure about that answer. PLEASE
explain the SOLUTION IN DETAIL. Thank you!
department salary status соиnt age 31... 35 sales 46K. ..50K 30 senior 26K. .. 30K 31K... 35K...
Given a data tuple having the values “systems,” “26...30,” and
“46–50K” for the attributes department, age, and salarry,
respectively, what would naiive Bayesian classification of the
status for the tuple be? The answer is "P(X|senior) = 0;
P(X|junior) = 0.018. Thus, a naiive Bayesian classification
predicts “junior”." Or I am not sure about that answer. PLEASE
explain the SOLUTION IN DETAIL. Thank you!
department salary status соиnt age 31... 35 sales 46K. ..50K 30 senior 26K. .. 30K 31K... 35K...
 The following table consists of training data from an employee
database. The data
have been generalized. For example, “31 . . . 35” for age
represents the age range
of 31 to 35. For a given row entry, count represents the
number of data tuples
having the values for department, status, age, and salary
given in that row.
department status age salary count
sales senior 31. . . 35 46K. . . 50K 30
sales junior 26. . . 30...
The following table consists of training data from an employee
database. The data
have been generalized. For example, “31 . . . 35” for age
represents the age range
of 31 to 35. For a given row entry, count represents the
number of data tuples
having the values for department, status, age, and salary
given in that row.
department status age salary count
sales senior 31. . . 35 46K. . . 50K 30
sales junior 26. . . 30...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago