


Homework Answers
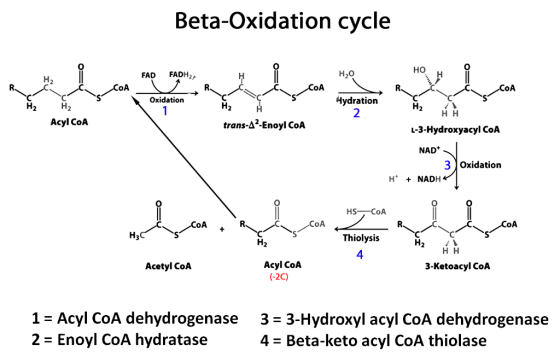
Beta-oxidation of Behenic acid:
It is a 22C containing saturated fatty acid.
1 NADH = 2.5 ATP
1 FADH2 = 1.5 ATP
1. Number of carbon atoms = 22
2. Number of acetyl CoA produced = 22/2 = 11
3. Number of beta-oxidation cycles = (22/2)-1 = 10
4. Number of NADH produced from the fatty acid spiral = 10
5. Number of FADH2 produced from the fatty acid spiral = 10
6. Number of ATP produced from Acetyl CoA by TCA cycle = 11 X 10 =
110
7. Number of ATP produced from NADH = 10 X 2.5 = 25
8. Number of ATP produced from FADH2 = 10 X 1.5 = 15
9. Total ATP produced = 110+25+15 = 150
10. Number of ATP required for activation = 2
11. Net yield = 148 ATP
Add Answer to:
Fatty Acid Metabolism. The reactions of the fatty acid spiral are shown below. Use the description...
(91 fatty Acid Metabolism. The reactions of the fatty acid spiral are shown below. Use the...
 (91 fatty Acid Metabolism. The reactions of the fatty acid spiral are shown below. Use the description on the left side of the page to classify the reactions and fil in the boxes on the right side of the page Aetivation Step. The activation of the fatty acid begins by the addition of CoA which will carry the fatty acid from the cytosol into the mitochondria. The product, which is a fatty acid with a CoA attached, is known as...
(91 fatty Acid Metabolism. The reactions of the fatty acid spiral are shown below. Use the description on the left side of the page to classify the reactions and fil in the boxes on the right side of the page Aetivation Step. The activation of the fatty acid begins by the addition of CoA which will carry the fatty acid from the cytosol into the mitochondria. The product, which is a fatty acid with a CoA attached, is known as...
EOS Fatty acid metabolism: Q1 1 point possible (graded) Fatty acid synthase is primed with two...
 EOS Fatty acid metabolism: Q1 1 point possible (graded) Fatty acid synthase is primed with two molecules at the beginning of odd-chain fatty acid synthesis. What are these TWO molecules? Propionyl-COA Palmitoyl-CoA Malonyl-CoA Acetyl-COA I Acyl-Coa union How many molecules of malonyl-CoA would be invested to synthesize one molecule of the fatty acid shown above? How many molecules of NADPH would be invested to synthesize one molecule of the fatty acid shown above? How many molecules of ATP would be...
EOS Fatty acid metabolism: Q1 1 point possible (graded) Fatty acid synthase is primed with two molecules at the beginning of odd-chain fatty acid synthesis. What are these TWO molecules? Propionyl-COA Palmitoyl-CoA Malonyl-CoA Acetyl-COA I Acyl-Coa union How many molecules of malonyl-CoA would be invested to synthesize one molecule of the fatty acid shown above? How many molecules of NADPH would be invested to synthesize one molecule of the fatty acid shown above? How many molecules of ATP would be...
2) Use this intermediate in fatty acid synthesis ACP The synthesis of this intermediate required one...
 2) Use this intermediate in fatty acid synthesis ACP The synthesis of this intermediate required one molecule of malonyl CoA two molecules of malony CoA three molecules of malonyl COA four molecules of malony CoA five molecules of malonyl COA Not listed 7) The molecules shown below are intermediates found in one round of fatty acid synthesis after the condensation step. so ACP ACP Which round of fatty acid synthesis is occurring in the reactions shown? The intermediate above is...
2) Use this intermediate in fatty acid synthesis ACP The synthesis of this intermediate required one molecule of malonyl CoA two molecules of malony CoA three molecules of malonyl COA four molecules of malony CoA five molecules of malonyl COA Not listed 7) The molecules shown below are intermediates found in one round of fatty acid synthesis after the condensation step. so ACP ACP Which round of fatty acid synthesis is occurring in the reactions shown? The intermediate above is...
Fatty Acid Catabolism (B Oxidation) Examine Figure 12.15 to answer the questions below. B carbon -SCOA...
 Fatty Acid Catabolism (B Oxidation) Examine Figure 12.15 to answer the questions below. B carbon -SCOA 000000000000000 Fatty acyl CoA of 18C FAD FADH 00000000000000000 scoa @]H40 00000000000000001_scoa or NAD" HO HO -SCOA NAD K.NADH + H NADH+H* 0 0 000-SCOA 0000000000 © COA-SH -SCOA 0 0000000000000000-SCA Fatty acyl CoA of 16C repeats cycle (reactions 1-4) QUESTIONS 1. How is the fatty acyl CoA at the top of the cycle different from the fatty acyl COA at the bottom of...
Fatty Acid Catabolism (B Oxidation) Examine Figure 12.15 to answer the questions below. B carbon -SCOA 000000000000000 Fatty acyl CoA of 18C FAD FADH 00000000000000000 scoa @]H40 00000000000000001_scoa or NAD" HO HO -SCOA NAD K.NADH + H NADH+H* 0 0 000-SCOA 0000000000 © COA-SH -SCOA 0 0000000000000000-SCA Fatty acyl CoA of 16C repeats cycle (reactions 1-4) QUESTIONS 1. How is the fatty acyl CoA at the top of the cycle different from the fatty acyl COA at the bottom of...
Question 1. Calculate the numbers of acetyl-CoA molecules produced when a fatty acid with 14 carbons...
 Question 1. Calculate the numbers of acetyl-CoA molecules produced when a fatty acid with 14 carbons after undergoing beta-oxidation? Question 2. How many a) cycles of beta-oxidation will a fatty acid with 14 carbons undergo? Explain briefly. b)? How many acetyl-CoA molecules ? explain briefly? Question 3. Consider the synthesis of fatty acids: Answer the flowing: True or False: a) CoA carries intermediate b) Acetyl-CoA donates two carbon atoms c) Malonyl-CoA donates two carbon atoms d) The reverse of fatty...
Question 1. Calculate the numbers of acetyl-CoA molecules produced when a fatty acid with 14 carbons after undergoing beta-oxidation? Question 2. How many a) cycles of beta-oxidation will a fatty acid with 14 carbons undergo? Explain briefly. b)? How many acetyl-CoA molecules ? explain briefly? Question 3. Consider the synthesis of fatty acids: Answer the flowing: True or False: a) CoA carries intermediate b) Acetyl-CoA donates two carbon atoms c) Malonyl-CoA donates two carbon atoms d) The reverse of fatty...
Complete the sentences to correctly describe steps in fatty acid synthesis. Put the terms to the...
Complete the sentences to correctly describe steps in fatty acid synthesis. Put the terms to the appropriate blanks. Some terms will not be used, and some will be used more than once. Fatty acid synthesis begins with a preparatory step in which ____________ is transferred from ___________ to the ___________. However, it cannot pass through the membrane, so it is transported as ___________, which is cleaved to ____________ and ____________. In the cytosol, acetyl CoA is converted to ____________, a...
An activated fatty acid (acyl-CoA) can be transported into the mitochondria for b-oxidation or remain in...
An activated fatty acid (acyl-CoA) can be transported into the mitochondria for b-oxidation or remain in the cytosol for lipogenesis to produce a triacylglycerol. What regulates the fate of this acyl-CoA? A. the amount of acyl-CoA in the mitochondria B. the amount of acyl-carnitine in the mitochondria C. the amount of NADH in the cytoplasm D. the amount of malonyl CoA in the cytoplasm E. the amount of acetyl-CoA in the cytoplasm
4. During the last step of the β-oxidation pathway for fatty acids, the intermediate below is con...
 Solve all
4. During the last step of the β-oxidation pathway for fatty acids, the intermediate below is converted to CH3 (CH2) 12ČCH2C-SCoA a. CH3 (CH2) 12C00H + CoA b. 2 CH3C-SCOA CH3 (CH2) 126CH2CHsCH3C-SCoA d. 5. The intermediate below is produced during the fatty acid synthesis pathway. The next reaction of the pathway at the double bond, involves which type of reaction? CH3 (CH2 ) 12CH=CHCH2-ACP -CH2CH2OH- d. none of the above 6. The product of the first step...
Solve all
4. During the last step of the β-oxidation pathway for fatty acids, the intermediate below is converted to CH3 (CH2) 12ČCH2C-SCoA a. CH3 (CH2) 12C00H + CoA b. 2 CH3C-SCOA CH3 (CH2) 126CH2CHsCH3C-SCoA d. 5. The intermediate below is produced during the fatty acid synthesis pathway. The next reaction of the pathway at the double bond, involves which type of reaction? CH3 (CH2 ) 12CH=CHCH2-ACP -CH2CH2OH- d. none of the above 6. The product of the first step...
(1) put the molecule of the first round of lipogenesis in correct order (a) acetoacetyl-Acp (b)...
(1) put the molecule of the first round of lipogenesis in correct order (a) acetoacetyl-Acp (b) 3-hydroxyacyl-Acp (c)malanyl Acp (d) trans-2-enoyl Acp (e) butynyl-Acp (2) put the intermediate of the B oxidation of fatty acids in order from first to last. to rank items as equivalent overlap them (a) fatty acyl coA (b)trans-enoyl CoA (c) B-hydroxyacyl CoA (d) B-keotoacyl CoA (e)Acetyl CoA (3) what is the total number of ATP molecules that can be produced from the complete oxidation of...
1A) How many rounds/cycles of beta-oxidation would be needed to completely break down a 16-carbon fatty...
 1A) How many rounds/cycles of beta-oxidation would be needed to
completely break down a 16-carbon fatty acid molecule?
8
6
10
7
9
1B) What type of reaction is step 2?
isomerization
hydration
oxidation-reduction reaction
hydrolysis
1C) What type of enzyme catalyzes step 3?
oxidoreductase
lyase
hydrolase
transferase
ligase
1D) How many net ATP equivalents are generated
by the complete break down of a 12-Carbon fatty acid molecule?
97 ATP
95 ATP
100 ATP
146 ATP
124 ATP
117 ATP...
1A) How many rounds/cycles of beta-oxidation would be needed to
completely break down a 16-carbon fatty acid molecule?
8
6
10
7
9
1B) What type of reaction is step 2?
isomerization
hydration
oxidation-reduction reaction
hydrolysis
1C) What type of enzyme catalyzes step 3?
oxidoreductase
lyase
hydrolase
transferase
ligase
1D) How many net ATP equivalents are generated
by the complete break down of a 12-Carbon fatty acid molecule?
97 ATP
95 ATP
100 ATP
146 ATP
124 ATP
117 ATP...
 (91 fatty Acid Metabolism. The reactions of the fatty acid spiral are shown below. Use the description on the left side of the page to classify the reactions and fil in the boxes on the right side of the page Aetivation Step. The activation of the fatty acid begins by the addition of CoA which will carry the fatty acid from the cytosol into the mitochondria. The product, which is a fatty acid with a CoA attached, is known as...
(91 fatty Acid Metabolism. The reactions of the fatty acid spiral are shown below. Use the description on the left side of the page to classify the reactions and fil in the boxes on the right side of the page Aetivation Step. The activation of the fatty acid begins by the addition of CoA which will carry the fatty acid from the cytosol into the mitochondria. The product, which is a fatty acid with a CoA attached, is known as...
 EOS Fatty acid metabolism: Q1 1 point possible (graded) Fatty acid synthase is primed with two molecules at the beginning of odd-chain fatty acid synthesis. What are these TWO molecules? Propionyl-COA Palmitoyl-CoA Malonyl-CoA Acetyl-COA I Acyl-Coa union How many molecules of malonyl-CoA would be invested to synthesize one molecule of the fatty acid shown above? How many molecules of NADPH would be invested to synthesize one molecule of the fatty acid shown above? How many molecules of ATP would be...
EOS Fatty acid metabolism: Q1 1 point possible (graded) Fatty acid synthase is primed with two molecules at the beginning of odd-chain fatty acid synthesis. What are these TWO molecules? Propionyl-COA Palmitoyl-CoA Malonyl-CoA Acetyl-COA I Acyl-Coa union How many molecules of malonyl-CoA would be invested to synthesize one molecule of the fatty acid shown above? How many molecules of NADPH would be invested to synthesize one molecule of the fatty acid shown above? How many molecules of ATP would be...
 2) Use this intermediate in fatty acid synthesis ACP The synthesis of this intermediate required one molecule of malonyl CoA two molecules of malony CoA three molecules of malonyl COA four molecules of malony CoA five molecules of malonyl COA Not listed 7) The molecules shown below are intermediates found in one round of fatty acid synthesis after the condensation step. so ACP ACP Which round of fatty acid synthesis is occurring in the reactions shown? The intermediate above is...
2) Use this intermediate in fatty acid synthesis ACP The synthesis of this intermediate required one molecule of malonyl CoA two molecules of malony CoA three molecules of malonyl COA four molecules of malony CoA five molecules of malonyl COA Not listed 7) The molecules shown below are intermediates found in one round of fatty acid synthesis after the condensation step. so ACP ACP Which round of fatty acid synthesis is occurring in the reactions shown? The intermediate above is...
 Fatty Acid Catabolism (B Oxidation) Examine Figure 12.15 to answer the questions below. B carbon -SCOA 000000000000000 Fatty acyl CoA of 18C FAD FADH 00000000000000000 scoa @]H40 00000000000000001_scoa or NAD" HO HO -SCOA NAD K.NADH + H NADH+H* 0 0 000-SCOA 0000000000 © COA-SH -SCOA 0 0000000000000000-SCA Fatty acyl CoA of 16C repeats cycle (reactions 1-4) QUESTIONS 1. How is the fatty acyl CoA at the top of the cycle different from the fatty acyl COA at the bottom of...
Fatty Acid Catabolism (B Oxidation) Examine Figure 12.15 to answer the questions below. B carbon -SCOA 000000000000000 Fatty acyl CoA of 18C FAD FADH 00000000000000000 scoa @]H40 00000000000000001_scoa or NAD" HO HO -SCOA NAD K.NADH + H NADH+H* 0 0 000-SCOA 0000000000 © COA-SH -SCOA 0 0000000000000000-SCA Fatty acyl CoA of 16C repeats cycle (reactions 1-4) QUESTIONS 1. How is the fatty acyl CoA at the top of the cycle different from the fatty acyl COA at the bottom of...
 Question 1. Calculate the numbers of acetyl-CoA molecules produced when a fatty acid with 14 carbons after undergoing beta-oxidation? Question 2. How many a) cycles of beta-oxidation will a fatty acid with 14 carbons undergo? Explain briefly. b)? How many acetyl-CoA molecules ? explain briefly? Question 3. Consider the synthesis of fatty acids: Answer the flowing: True or False: a) CoA carries intermediate b) Acetyl-CoA donates two carbon atoms c) Malonyl-CoA donates two carbon atoms d) The reverse of fatty...
Question 1. Calculate the numbers of acetyl-CoA molecules produced when a fatty acid with 14 carbons after undergoing beta-oxidation? Question 2. How many a) cycles of beta-oxidation will a fatty acid with 14 carbons undergo? Explain briefly. b)? How many acetyl-CoA molecules ? explain briefly? Question 3. Consider the synthesis of fatty acids: Answer the flowing: True or False: a) CoA carries intermediate b) Acetyl-CoA donates two carbon atoms c) Malonyl-CoA donates two carbon atoms d) The reverse of fatty...
 Solve all
4. During the last step of the β-oxidation pathway for fatty acids, the intermediate below is converted to CH3 (CH2) 12ČCH2C-SCoA a. CH3 (CH2) 12C00H + CoA b. 2 CH3C-SCOA CH3 (CH2) 126CH2CHsCH3C-SCoA d. 5. The intermediate below is produced during the fatty acid synthesis pathway. The next reaction of the pathway at the double bond, involves which type of reaction? CH3 (CH2 ) 12CH=CHCH2-ACP -CH2CH2OH- d. none of the above 6. The product of the first step...
Solve all
4. During the last step of the β-oxidation pathway for fatty acids, the intermediate below is converted to CH3 (CH2) 12ČCH2C-SCoA a. CH3 (CH2) 12C00H + CoA b. 2 CH3C-SCOA CH3 (CH2) 126CH2CHsCH3C-SCoA d. 5. The intermediate below is produced during the fatty acid synthesis pathway. The next reaction of the pathway at the double bond, involves which type of reaction? CH3 (CH2 ) 12CH=CHCH2-ACP -CH2CH2OH- d. none of the above 6. The product of the first step...
 1A) How many rounds/cycles of beta-oxidation would be needed to
completely break down a 16-carbon fatty acid molecule?
8
6
10
7
9
1B) What type of reaction is step 2?
isomerization
hydration
oxidation-reduction reaction
hydrolysis
1C) What type of enzyme catalyzes step 3?
oxidoreductase
lyase
hydrolase
transferase
ligase
1D) How many net ATP equivalents are generated
by the complete break down of a 12-Carbon fatty acid molecule?
97 ATP
95 ATP
100 ATP
146 ATP
124 ATP
117 ATP...
1A) How many rounds/cycles of beta-oxidation would be needed to
completely break down a 16-carbon fatty acid molecule?
8
6
10
7
9
1B) What type of reaction is step 2?
isomerization
hydration
oxidation-reduction reaction
hydrolysis
1C) What type of enzyme catalyzes step 3?
oxidoreductase
lyase
hydrolase
transferase
ligase
1D) How many net ATP equivalents are generated
by the complete break down of a 12-Carbon fatty acid molecule?
97 ATP
95 ATP
100 ATP
146 ATP
124 ATP
117 ATP...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 11 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 11 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 11 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 11 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 11 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 11 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 11 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 11 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 11 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 11 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 11 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 11 months ago