Intro. to Business Intelligence List and briefly define the central tendency measures of descriptive statistics. (well...
Intro. to Business Intelligence
List and briefly define the central tendency measures of descriptive statistics.
(well answered please)
Homework Answers
To represent a dataset, we cannot use all the values of the
dataset all the time. If we use all the values of the dataset
representation purpose, it becomes cumbersome for large datasets.
Even in cases, when we want to compare the datasets, it becomes
hard because the datasets can be of different sizes.
In these cases, the central measure becomes important to represent
the entire dataset by a single value. This single value is nothing
but a summary of the entire dataset. The central value tells about
a value that is ideally located at the center of the various data
points in the dataset. This central value is also helpful in
identifying the outliers in a dataset by comparing the data points
in the dataset with this central value. The values with an extreme
separation from this data point can be called as outlies.
Similarly, these are also used to compare the different datasets.
There are multiple mathematical tests that are based on these
central values. The tests need not compare every data point in the
datasets with each other, instead, we can compare these central
values.
The three most commonly used central tendency measures are:
- Mean
- Median
- Mode
Mean:
Mean is one of the most commonly used measures. It is also known as
average. It can be calculated by dividing the summation of all the
numbers in the dataset by the total count of numbers in the
dataset.
For e.g. a dataset with numbers such as 32, 32, 32, 33 ,33, 34,
37,39,51
The sum of the digits is 323 and the count of digits in the dataset
is 9.
The mean will be nothing but the sum of the digits in the dataset
divided by the count of digits in the dataset that will be
323 divided by 9 or 323 / 9 i.e.35.89
The representation of mean for the population is given by
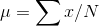
Here the summation of x represents the sum of all the numbers in the dataset while N represents the count of the numbers in the dataset.
For the sample, the mean is represented by M

The mean representation is susceptible to problems if there are outliers in the data. The ideal value of the mean gets skewed either at the high or low side based on the outlier values and their frequency. Generally, the mean is not one of the values of the dataset. It is best for continuous data.
Median:
The median gives the exact center value of the data. In the case
of the dataset, the median value lies at the center of the dataset.
There are equal values, above the median and equal values below the
median. For the purpose of calculating the median, the dataset
needs to be arranged from low to high values.
For e.g. our earlier dataset with numbers such as 32, 32, 32, 33
,33, 34, 37,39,51
This dataset is already sorted. The dataset has 9 digits so there
is an absolute central value. We will just use the 5th value i.e.
33 as the median. As we can see there are 4 values that lie on the
left of the dataset while there are 4 values that lie on the right
of the dataset. In case, if the dataset would have had 10 values,
we would have to calculate the mean of the 5th and 6th value to get
the median value.
Median works well for the datasets with outliers.
Mode:
The mode is nothing but a measure that gives the value with the
highest frequency as the mode value.
For e.g. our earlier dataset with numbers such as 32, 32, 32, 33
,33, 34, 37,39,51
Here 32 has frequency value as 3 while 33 has a frequency value 2.
All other digits have a frequency value of 1. As we can see, 32 has
the highest frequency among all these numbers. Thus the mode value
is 32.
This measure is especially good in discrete data. To depict the
mode in the continuous measure, we will have to club the data in
different buckets such as 0-10, 10-20, etc. For all these buckets,
we can have frequency and see, which bucket has the highest
frequency.
The problem with the mode is in cases where the frequency measures
of multiple numbers are the same. In those cases, it is hard to
decide upon the true mode value of the dataset.
Add Answer to:
Intro. to Business Intelligence
List and briefly define the central tendency measures of
descriptive statistics.
(well...
Summary of Descriptive Statistics Excel will tabulate a summary of the descriptive statistics for...
 Summary of Descriptive Statistics Excel will tabulate a summary of the descriptive statistics for central tendency and using the Data Analysis Pack. Click Data Click Data Analysis .In the pop-up list click on Descriptive Statistics and hit OK . In the pop-up box in the input range type A2:A75 or highlight this region . Click the box next to summary statistics Click OK A box of summary statistics will appear like the one below Mean Standard Error Median Mode Standard...
Summary of Descriptive Statistics Excel will tabulate a summary of the descriptive statistics for central tendency and using the Data Analysis Pack. Click Data Click Data Analysis .In the pop-up list click on Descriptive Statistics and hit OK . In the pop-up box in the input range type A2:A75 or highlight this region . Click the box next to summary statistics Click OK A box of summary statistics will appear like the one below Mean Standard Error Median Mode Standard...
Thanks HE RESEARCHER H3 MEASURES OF CENTRAL TENDENCY 85 The Typical American Is there such a...
 Thanks
HE RESEARCHER H3 MEASURES OF CENTRAL TENDENCY 85 The Typical American Is there such a thing as a "typical" American? In this of the average American based on measures of central tendency chosen by you from the 2012 General Social Survey (GS$2012. Choose variables that you think are the most important in defining what it means to be a member of this soch ety and then choose an appropriate measure of central tendency for each variable. Use this information...
Thanks
HE RESEARCHER H3 MEASURES OF CENTRAL TENDENCY 85 The Typical American Is there such a thing as a "typical" American? In this of the average American based on measures of central tendency chosen by you from the 2012 General Social Survey (GS$2012. Choose variables that you think are the most important in defining what it means to be a member of this soch ety and then choose an appropriate measure of central tendency for each variable. Use this information...
Summary and Descriptive Statistics
There is often the requirement to evaluate descriptive statistics for data within the organization or for health care information. Every year the National Cancer Institute collects and publishes data based on patient demographics. Understanding differences between the groups based upon the collected data often informs health care professionals towards research, treatment options, or patient education.Using the data on the "National Cancer Institute Data" Excel spreadsheet, calculate the descriptive statistics indicated below for each of the Race/Ethnicity groups. Refer to your...
Describe the data with the tools of descriptive statistics, using both numerical as well as graphical...
Describe the data with the tools of descriptive statistics, using both numerical as well as graphical methods. In addition to reporting and commenting on the values central tendency and diagrams, please also justify the choice of method (e.g. why a particular kind of measure of central tendency was selected and the chosen graphic is appropriate to use in this context). Shift Stress 1 2 1 5 1 7 1 8 1 5 1 4 1 3 1 6 1 5...
Describe the data with the tools of descriptive statistics, using both numerical as well as graphical...
Describe the data with the tools of descriptive statistics, using both numerical as well as graphical methods. In addition to reporting and commenting on the values central tendency and diagrams, please also justify the choice of method (e.g. why a particular kind of measure of central tendency was selected and the chosen graphic is appropriate to use in this context Price Quantity supplied 14,5 7 13,4 8 12,7 6 16,4 10 21 15 13,9 11 17,3 21 12,5 10 16,7...
Describe the difference between descriptive and inferential statistics Identify the level of measurement of a variety...
Describe the difference between descriptive and inferential statistics Identify the level of measurement of a variety of variables Describe the difference between measures of central tendency and variability Explain the difference between correlation and causation Describe measurement validity and reliability and name the statistics used to test them Explain the difference between a population and a sample Describe what correlations are and how they are used only answer if you know these. Thanks.
QUESTION: How would one define business intelligence (BI)? Identify and briefly discuss a real-world application of...
QUESTION: How would one define business intelligence (BI)? Identify and briefly discuss a real-world application of BI? Please DO NOT copy-paste from other sources. The answer will be checked for plagiarism. Just 250 of your own words more than enough. Thank you!!!
How would one define business intelligence (BI)? Identify and briefly discuss a real-world application of BI?...
How would one define business intelligence (BI)? Identify and briefly discuss a real-world application of BI? Need 300 own words with no plagrism
Below is are the measures of central tendency and dispersion for the number of victims killed...
 Below is are the measures of central tendency and dispersion for
the number of victims killed in mass killing events. Using the
information below, answer the following questions.
Would you say that the data is skewed? Why or why not?
What is the range of for number of victims killing in a mass
killing?
At what number of victims does 95% of the distribution
cover?
Statistics number of victims NValid 297 Missing Mean Median Mode Std. Deviation Minimum Maximum 4.98...
Below is are the measures of central tendency and dispersion for
the number of victims killed in mass killing events. Using the
information below, answer the following questions.
Would you say that the data is skewed? Why or why not?
What is the range of for number of victims killing in a mass
killing?
At what number of victims does 95% of the distribution
cover?
Statistics number of victims NValid 297 Missing Mean Median Mode Std. Deviation Minimum Maximum 4.98...
There are four measures of central tendency that we will study this week. They may yield...
There are four measures of central tendency that we will study this week. They may yield different results for the same set of data. They each really serve the same purpose in different ways. Please share your idea of when one may hope to have a higher measure of center and in which situation one may hope to have a lower measure of center for a set of data. For example, if I am a business owner, then I may...
 Summary of Descriptive Statistics Excel will tabulate a summary of the descriptive statistics for central tendency and using the Data Analysis Pack. Click Data Click Data Analysis .In the pop-up list click on Descriptive Statistics and hit OK . In the pop-up box in the input range type A2:A75 or highlight this region . Click the box next to summary statistics Click OK A box of summary statistics will appear like the one below Mean Standard Error Median Mode Standard...
Summary of Descriptive Statistics Excel will tabulate a summary of the descriptive statistics for central tendency and using the Data Analysis Pack. Click Data Click Data Analysis .In the pop-up list click on Descriptive Statistics and hit OK . In the pop-up box in the input range type A2:A75 or highlight this region . Click the box next to summary statistics Click OK A box of summary statistics will appear like the one below Mean Standard Error Median Mode Standard...
 Thanks
HE RESEARCHER H3 MEASURES OF CENTRAL TENDENCY 85 The Typical American Is there such a thing as a "typical" American? In this of the average American based on measures of central tendency chosen by you from the 2012 General Social Survey (GS$2012. Choose variables that you think are the most important in defining what it means to be a member of this soch ety and then choose an appropriate measure of central tendency for each variable. Use this information...
Thanks
HE RESEARCHER H3 MEASURES OF CENTRAL TENDENCY 85 The Typical American Is there such a thing as a "typical" American? In this of the average American based on measures of central tendency chosen by you from the 2012 General Social Survey (GS$2012. Choose variables that you think are the most important in defining what it means to be a member of this soch ety and then choose an appropriate measure of central tendency for each variable. Use this information...
 Below is are the measures of central tendency and dispersion for
the number of victims killed in mass killing events. Using the
information below, answer the following questions.
Would you say that the data is skewed? Why or why not?
What is the range of for number of victims killing in a mass
killing?
At what number of victims does 95% of the distribution
cover?
Statistics number of victims NValid 297 Missing Mean Median Mode Std. Deviation Minimum Maximum 4.98...
Below is are the measures of central tendency and dispersion for
the number of victims killed in mass killing events. Using the
information below, answer the following questions.
Would you say that the data is skewed? Why or why not?
What is the range of for number of victims killing in a mass
killing?
At what number of victims does 95% of the distribution
cover?
Statistics number of victims NValid 297 Missing Mean Median Mode Std. Deviation Minimum Maximum 4.98...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago