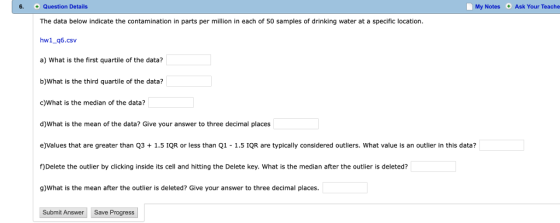
Data:
contamination 418 396 400 404 398 413 411 403 410 393 384 415 421 391 398 408 384 396 410 388 406 407 422 422 2321 415 388 426 394 415 411 410 396 426 422 404 414 410 410 401 392 396 415 409 384 426 402 396 392 406
Homework Answers
Here we have data:
384,384,384,388,388,391,392,392,393,394,396,396,396,396,396,398,398,400,401,402,403,404,404,406,406,407,408,409,410,410,410,410,410,411,411,413,414,415,415,415,415,418,421,422,422,422,426,426,426,2321
a) first quartile = 396
b) third quartile = 415
c) median = 406.5
d) Mean = 443.580
e) Outlier of data = 2321
f) median after outlier deleted = 406
g) Mean of the data after outlier deleted = 405.265
Add Answer to:
Data: contamination 418 396 400 404 398 413 411 403 410 393 384 415 421 391...
The data below indicate the contamination in parts per million in each of 50 samples of...
The data below indicate the contamination in parts per million in each of 50 samples of drinking water at a specific location. hw1_q6a a) What is the first quartile of the data? b)What is the third quartile of the data? c)What is the median of the data? d)What is the mean of the data? Give your answer to three decimal places e)Values that are greater than Q3 + 1.5 IQR or less than Q1 - 1.5 IQR are typically considered...
6. + Question Details The data below indicate the contamination in parts per ilin in each...
 6. + Question Details The data below indicate the contamination in parts per ilin in each of 50 samples of drinking water at a specific location hw1_q6.csv a) What is the first quartile of the data? b)What is the third quartile of the data? c)What is the median of the data? d)What is the mean of the data? Give your answer to three decimal places e)Values that are greater than Q3 1.5 IQR or less than Q1 1.5 IQR are...
6. + Question Details The data below indicate the contamination in parts per ilin in each of 50 samples of drinking water at a specific location hw1_q6.csv a) What is the first quartile of the data? b)What is the third quartile of the data? c)What is the median of the data? d)What is the mean of the data? Give your answer to three decimal places e)Values that are greater than Q3 1.5 IQR or less than Q1 1.5 IQR are...
Hi it's python I imported a data which are so many words in txt and I arranged and reshaped with ...
 Hi it's python I imported a data which are so many words in txt
and I arranged and reshaped with alphabetically both rows and
columns
I was successful with these steps but I am stuck with next
step
below is my code and screenshot
import numpy as np
import pandas as pd
data=pd.read_csv("/Users/superman/Downloads/words_file2.txt",header=None)
df_input=pd.DataFrame(data)
df_output=pd.DataFrame(np.arange(676).reshape((26,26)),
index =
['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'],
columns =
['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'])
df_output.index.name="Start"
df_output.columns.name="End"
df_output
This below screen shot is what I have to find
I have to find each word...
Hi it's python I imported a data which are so many words in txt
and I arranged and reshaped with alphabetically both rows and
columns
I was successful with these steps but I am stuck with next
step
below is my code and screenshot
import numpy as np
import pandas as pd
data=pd.read_csv("/Users/superman/Downloads/words_file2.txt",header=None)
df_input=pd.DataFrame(data)
df_output=pd.DataFrame(np.arange(676).reshape((26,26)),
index =
['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'],
columns =
['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'])
df_output.index.name="Start"
df_output.columns.name="End"
df_output
This below screen shot is what I have to find
I have to find each word...
 6. + Question Details The data below indicate the contamination in parts per ilin in each of 50 samples of drinking water at a specific location hw1_q6.csv a) What is the first quartile of the data? b)What is the third quartile of the data? c)What is the median of the data? d)What is the mean of the data? Give your answer to three decimal places e)Values that are greater than Q3 1.5 IQR or less than Q1 1.5 IQR are...
6. + Question Details The data below indicate the contamination in parts per ilin in each of 50 samples of drinking water at a specific location hw1_q6.csv a) What is the first quartile of the data? b)What is the third quartile of the data? c)What is the median of the data? d)What is the mean of the data? Give your answer to three decimal places e)Values that are greater than Q3 1.5 IQR or less than Q1 1.5 IQR are...
 Hi it's python I imported a data which are so many words in txt
and I arranged and reshaped with alphabetically both rows and
columns
I was successful with these steps but I am stuck with next
step
below is my code and screenshot
import numpy as np
import pandas as pd
data=pd.read_csv("/Users/superman/Downloads/words_file2.txt",header=None)
df_input=pd.DataFrame(data)
df_output=pd.DataFrame(np.arange(676).reshape((26,26)),
index =
['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'],
columns =
['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'])
df_output.index.name="Start"
df_output.columns.name="End"
df_output
This below screen shot is what I have to find
I have to find each word...
Hi it's python I imported a data which are so many words in txt
and I arranged and reshaped with alphabetically both rows and
columns
I was successful with these steps but I am stuck with next
step
below is my code and screenshot
import numpy as np
import pandas as pd
data=pd.read_csv("/Users/superman/Downloads/words_file2.txt",header=None)
df_input=pd.DataFrame(data)
df_output=pd.DataFrame(np.arange(676).reshape((26,26)),
index =
['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'],
columns =
['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'])
df_output.index.name="Start"
df_output.columns.name="End"
df_output
This below screen shot is what I have to find
I have to find each word...
Most questions answered within 3 hours.
-
Where is the error in this code sequence?
String s1 = "Hello";
String s2 = "ello";...
asked 10 months ago -
Financial data for Joel de Paris, Inc., for last year
follow:
Joel de Paris, Inc.
Balance...
asked 10 months ago -
Consider this reaction:
Al2(SO4)3 (aq)+ BaCl3
(aq) Al2Cl6 (aq)- +
3BaSO4(s) . What is the...
asked 10 months ago -
Suppose that Savneet is considering increasing her
recent random sample from 20 car rentals to 40...
asked 10 months ago -
Trucks arrive at an unloading terminal at an average rate of 120
per hour.
Trucks arrive...
asked 10 months ago -
Why are methanol and ethanol completely soluble in water while
octanol is not very little soluble....
asked 10 months ago -
A facilities manager at a university reads in a research report
that the mean amount of...
asked 10 months ago -
When the CuSO4 is rehydrated by adding water to the anhydrous
compound, is this an endothermic...
asked 10 months ago -
A ray of sunlight is passing from diamond into crown glass; the
angle of incidence is...
asked 10 months ago -
A block of mass 0.249 kg is placed on top of a light, vertical
spring of...
asked 10 months ago -
how do the kidneys compensate in the presences of acidosis
a) trigger hyperventilate
b) reserve acid...
asked 10 months ago -
Question 501 pts
The rental rate of capital to the firm increases. Which of the
following...
asked 10 months ago